인류 역사 상 위대한 천재 중 한 명으로 꼽히는 폰 노이만(Von Neumann)이라는 인물에 관해 들어본 적이 있는가? 그는 미국에서 수학자 및 물리학자로서 넓은 분야에 걸쳐 활동하던 인물인데, 컴퓨터 분야에서도 지금까지 회자될 만큼의 위대한 업적을 남겼다. 바로 현대 컴퓨터의 기본 구조를 확립한 것이다. EDVAC이라는 컴퓨터에 대한 보고서의 최초 초안에서 메모리에 프로그램이 저장되는 방식을 소개하며 훗날 '폰 노이만 모델(Von Neumann Model)'이라 불리는 컴퓨터 아키텍처를 제안했는데, 그 방식이 지금까지도 컴퓨터를 만드는 기본 구조로 채택되고 있다. 그렇다면 폰 노이만 모델이라는 게 무엇인지 이번 포스팅에서 한 번 알아보도록 하자.
1. 폰 노이만 모델 (Von Neumann Model)
현대 컴퓨터의 기본 골격으로서 채택된 폰 노이만 모델에 따르면, 컴퓨터는 다음 그림과 같이 다섯 가지 부분으로 나뉘게 된다.

다섯 가지 부분 각각을 간단히 요약하면 다음과 같다. 자세한 내용은 이어서 설명하는 부분을 참조하자.
| 부분 | 역할 |
| 메모리 (Memory) | 데이터 혹은 프로그램의 코드가 저장되는 부분이다. MAR(Memory Address Register)은 접근하고자 하는 메모리 location의 주소를 임시로 저장하는 레지스터, MDR(Memory Data Register)은 메모리로부터 읽힌 데이터 혹은 메모리에 쓰고자 하는 데이터를 임시로 저장하는 레지스터이다. MAR과 MDR은 CPU가 메모리와 통신하기 위 인터페이스 역할의 레지스터이다. |
| 처리 장치 (Processing Unit) | 실제로 데이터에 대한 연산을 처리하기 위한 부분이다. 입력된 데이터에 대한 연산을 수행하는 ALU(Arithmetic Logic Unit)라는 회로와 연산 중간 결과물을 담는 몇 개의 TEMP 레지스터 등으로 이루어진다. 컨트롤 유닛과 함께 CPU를 구성하는 한 부분이다. |
| 컨트롤 유닛 (Control Unit) | 프로그램 코드에 해당하는 명령어를 읽고 해석하여 지시된 명령을 수행하는 과정 전반에서 지휘자 역할을 담당하는 부분이다. 다음에 읽어들일 명령어의 메모리 location 주소를 저장하는 PC(Program Counter), 현재 읽어들여 실행 중인 명령어를 저장하는 IR(Instruction Register), 명령어 해석 및 수행 과정 전반을 통제하는 유한 상태 기계가 존재하는 부분이다. 처리 장치와 함께 CPU를 구성하는 한 부분이다. |
| 입력 장치 (Input) | 키보드, 마우스, 스캐너 등과 같이 메모리 외부에서 원하는 데이터를 메모리 내부에 입력하기 위한 장치를 의미한다. 또한 하드 디스크와 같은 저장 장치도 메모리가 데이터를 읽어올 수 있으므로 입력 장치에 속한다. |
| 출력 장치 (Output) | 모니터, 프린터, LED 등과 같이 메모리 내부에 존재하는 데이터를 메모리 외부에 출력하기 위한 장치를 의미한다. 또한 하드 디스크와 같은 저장 장치도 메모리가 데이터를 쓸 수 있으므로 출력 장치에 속한다. |
2. 메모리 (Memory)
메모리 location의 주소를 k비트로 표현하는 CPU라면, 메모리가 가질 수 있는 location의 최대 개수는 2^k개가 된다. 그리고 메모리의 Addressability가 m비트라면 총 (2^k x m)비트의 데이터를 저장할 수 있는 메모리가 되는 것이다. 다음 그림은 4비트로 메모리 주소를 표현하는 CPU와 함께 사용되는, Addressability가 8비트인 메모리의 도식을 나타낸다. 참고로 우리가 공부할 LC-3 컴퓨터는 주소가 16비트로 표현되고 Addressability도 16비트인 메모리를 사용한다. 즉 (2^16 x 16)비트의 데이터를 저장할 수 있다.

CPU의 입장에서 메모리와 관련하여 수행할 수 있는 연산은 크게 두 종류이다. 바로 읽기(READ)와 쓰기(WRITE)이다. CPU가 메모리로부터 특정 데이터를 읽거나 메모리에 특정 데이터를 쓰기 위해서는, CPU가 메모리와 통신하기 위한 인터페이스 역할의 레지스터가 있어야 한다. 이것이 바로 앞서 설명했던 MAR과 MDR이다. 그럼 이러한 레지스터를 활용하여 메모리에 대한 읽기 및 쓰기 연산이 어떻게 이뤄지는지 한 번 알아보도록 하자.
| 연산 | 동작 원리 | 메모리에 입력해야 하는 신호 |
| 읽기 (READ) | 1. 읽고자 하는 데이터의 메모리 주소를 MAR에 저장한다. 2. 해당 메모리 주소에서 읽힌 데이터는 MDR에 저장된다. 3. MDR에 저장되어 있는 데이터를 읽어온다. |
메모리 주소 |
| 쓰기 (WRITE) | 1. 쓰고자 하는 데이터를 MDR에 저장한다. 2. 데이터를 쓰고자 하는 메모리 주소를 MAR에 저장한다. 3. 쓰기가 가능하도록 메모리에 WE 신호를 입력한다. |
메모리 주소 + 데이터 + WE |
3. 처리 장치 (Processing Unit)
처리 장치는 크게 두 부분으로 나뉜다. 하나는 덧셈이나 뺄셈 등의 연산을 실제로 수행하는 회로, 다른 하나는 그러한 연산의 과정에서 발생하는 결과물들을 임시로 저장하는 레지스터이다. 참고로 이러한 레지스터를 두고 범용 레지스터(General Purpose Register)라고 부르기도 한다(특정 목적을 위해 존재하는 게 아니라 여러 용도로 사용되는 레지스터이기 때문). 우리가 공부할 LC-3 CPU는 처리 장치가 ADD, AND, NOT 연산을 수행하는 회로와 16비트짜리 레지스터 8개로 이뤄져 있다.

그런데 하나 짚고 넘어갈 부분이 있다. 레지스터의 길이는 무엇을 의미할까? CPU마다 고유의 Word Length라는 것이 존재하는데, 이는 해당 CPU가 데이터를 처리하는 기본 단위를 의미한다. 예를 들어 Word Length가 16비트인 CPU라면 한 번에 처리하는 데이터의 단위가 16비트인 것이다. 물론 조금 더 엄밀히 얘기하면 Word Length는 CPU가 사용하는 ISA의 종류에 따라 달라진다. 그리고 그 Word Length가 바로 레지스터의 길이에 해당한다. CPU가 한 번에 처리하는 데이터의 길이만큼을 레지스터가 저장한다면 여러모로 구현이 간편해진다. 우리가 공부할 LC-3의 처리 장치에 있는 레지스터가 16비트짜리인 것도 LC-3가 정의하는 Word Length가 16비트이기 때문이다.
4. 입력 및 출력 장치 (Input and Output)
입출력 장치는 메모리와 데이터를 주고받는 외부 장치를 의미한다. 입출력 장치가 메모리와 데이터를 교환할 때는 중간에 CPU를 거치는데, 이를 위해서는 해당 입출력 장치가 CPU와 통신하기 위한 인터페이스로서의 레지스터를 가지고 있어야 한다. LC-3 컴퓨터의 경우 입출력 장치로서 모니터와 키보드를 지원하는데, 키보드는 KBDR(Keyboard Data Register)과 KBSR(Keyboard Status Register)이라는 인터페이스를, 모니터는 DDR(Display Data Register)과 DSR(Display Status Register)이라는 인터페이스를 가지고 있다. 이에 대한 자세한 내용은 이후 포스팅에서 설명할 예정이니 여기선 생략하도록 한다.

참고로 외부 장치에 대한 접근을 컨트롤하는 프로그램을 (장치) 드라이버라고 부른다. 우리가 프린터를 새로 구매하여 컴퓨터에 연결해서 사용하고자 할 때 다운로드하는 드라이버 프로그램이 이것의 대표적인 예시이다.
5. 컨트롤 유닛 (Control Unit)
프로그램의 코드에 해당하는 명령어들을 읽고 해석해서 원하는 동작을 수행하는 과정 전반을 통제하는 부분이다. 추상적으로 느껴지는 이 말을 이해하기 위해 하나씩 차근차근 알아보도록 하자. 참고로 이후부터 설명 과정 중간중간에 등장하는 각 종류의 명령어들과 ISA에 대한 내용은 바로 다음 포스팅에서 자세히 다룰 것이니, 여기서는 우선 간단히만 이해하고 넘어가자.
5-1. 프로그램의 동작이란? (간단하게)
먼저, 우리가 작성한 프로그램은 CPU의 ISA 체계에 맞는 0과 1로 이뤄진 명령어들로 번역이 되어 메모리의 연속적인 공간에 저장된다. CPU는 메모리에 저장되어 있는 명령어 하나를 읽고 해석하여 지시된 동작을 정확히 수행한 뒤, 방금 읽은 명령어의 바로 다음 위치에 존재하는 명령어를 읽어서 같은 과정을 반복하게 된다. 즉 프로그램이 동작한다는 것은 결국 '명령어 하나를 읽고 해석해서 지시된 동작을 수행하는 것'을 계속해서 반복하는 것뿐이다.
5-2. 명령어 (Instruction)
명령어(Instruction)란 정확히 무엇일까? 명령어도 여느 데이터와 마찬가지로 메모리에 저장되는 0과 1로 이뤄진 하나의 값일 뿐이다. 명령어의 길이는 명령어마다 다를 수도 있고 모두 동일할 수도 있는데, 우리가 공부할 LC-3의 경우에는 명령어의 길이가 Word Length에 해당하는 16비트로 고정되어 있다. 명령어는 크게 두 부분으로 구성되어 있다. 하나는 무슨 연산을 수행할지 명시하는 opcode(operation code의 약칭)이고, 다른 하나는 그 연산을 수행하는 데 필요한 데이터의 위치를 명시하는 부분이다.
명령어의 종류는 대략 다음과 같이 세 가지로 나눠서 생각해볼 수 있다. 첫 번째, '계산'을 위한 명령어이다. ADD, AND 등의 명령어가 이에 해당한다. 두 번째, '데이터 이동'을 위한 명령어이다. 메모리로부터 데이터를 읽어오는 LD 명령어나 메모리에 데이터를 쓰는 ST 명령이 이에 해당한다. 마지막으로, '흐름 제어'를 위한 명령어이다. 일반적으로는 순차적으로 실행되는 명령어의 흐름을 바꾸고 다른 명령어로 점프하고 싶은 경우에 사용하는 JMP, BRnz 명령어가 이에 해당한다. (앞서 밝힌 대로, 여기서 예시로 든 명령어는 모두 LC-3에 존재하는 명령어들이며 각각에 대한 설명은 이후 포스팅에서 자세히 다룰 것이므로 걱정하지 않아도 된다.)
참고로 해당 연산에 필요한 데이터의 위치(레지스터 혹은 메모리)를 명령어의 비트 위에 표현하는 방식을 주소지정방식(addressing mode)이라 부른다. 또한 명령어 하나는 완벽히 수행되거나 아예 수행되지 않아야 하는데, 이 특성을 atomic이라고 부른다.
5-3. ISA (Instruction Set Architecture)
나라의 언어마다 그 규칙이 존재하듯이, ISA도 그 종류마다 명령어의 종류, 자료형의 종류, 주소지정방식의 종류, Word Length가 모두 다르다. 예를 들어 어떤 ISA는 100가지의 명령어(즉 100개의 opcode)와 10가지의 자료형을 지원하는 반면, 어떤 ISA는 10가지의 명령어를 지원하고 자료형으로는 정수만 지원할 수도 있다. 전자의 ISA를 사용하는 CPU는 다소 복잡하게 구현이 될 것이고, 후자의 ISA를 사용하는 CPU는 그것보다는 단순하게 구현될 것이다. (앞서 밝힌 대로, ISA에 대한 자세한 설명은 이후 포스팅에서 다룰 것이다.)
5-4. PC (Program Counter), IR (Instruction Register), 유한 상태 기계 (Finite State Machine)
이제부터 본격적으로 컨트롤 유닛에 속한 장치들이 명령어의 해석 및 실행에 어떻게 관여하는지 알아보자. CPU는 PC에 저장되어 있는 주소를 읽어서 그 주소가 가리키는 메모리 공간에 접근하여 실행할 명령어를 읽어 들인다. 그렇게 읽어 들인 명령어는 IR에 저장이 되고, IR에 저장된 명령어를 CPU 내부에 위치한 Decoder로 해석하여 어떤 명령인지 파악하게 된다. 그리고 그 결과를 CPU 내부에 위치한 유한 상태 기계로 전달하면, 유한 상태 기계는 그 명령어를 실행하는 데 필요한 컨트롤 신호들을 활성화하고 나머지 컨트롤 신호들은 비활성화한 뒤 명령어 실행을 위한 첫 번째 단계(상태)에 돌입하게 된다. 가령 메모리에 특정 데이터를 쓰기 위한 명령어라면 메모리에 WE 신호를 활성화시켜야 한다.
결국 유한 상태 기계는 한 명령어를 수행하기 위해 여러 클락 사이클을 거치며 상태 전이를 거듭하게 되는데, 그러한 명령어들의 처리 절차는 대략 다음과 같이 요약해볼 수 있다. 즉 아래와 같은 6단계를 거치면서 하나의 명령어 실행이 완료된다. 물론 한 단계에 필요한 클락 사이클의 수는 단계마다 조금씩 다르다. 또한 모든 명령어가 이러한 6단계를 정확히 거치는 것은 아니어서, 어떤 명령어는 특정 단계에서 아무 동작도 수행하지 않을 수도 있다. 각 단계에 대한 자세한 내용은 바로 이어서 설명하는 부분을 참조하자.

5-5. 명령어 처리 절차 (Instruction Processing)
5-5-1. FETCH
메모리에 저장된 명령어를 읽어오는 과정이다. PC에 저장된 메모리 주소를 MAR에 저장하여 명령어를 MDR로 읽어 들이고, MDR에 저장된 명령어를 IR로 옮기면 된다. 그리고 PC의 값을 1만큼 증가시켜서 다음 FETCH를 수행할 때는 바로 다음에 위치한 명령어를 읽을 수 있게 한다.
5-5-2. DECODE
명령어가 어떤 종류의 명령인지 파악하는 과정이다. 명령어의 opcode에 해당하는 부분을 CPU 내 Decoder에 입력하여 어떤 명령인지 파악하고, 그것에 따라 opcode를 제외한 나머지 비트를 해석하는 방법을 결정하게 된다. 예를 들어 ADD 명령어는 opcode를 제외한 하위 비트 중 어떤 부분은 첫 번째 피연산자에 해당할 것이고, 어떤 부분은 두 번째 피연산자에 해당할 것이다.
5-5-3. EVALUATE ADDRESS
명령어가 필요로 하는 데이터가 메모리에 위치한 경우, 그 데이터가 위치한 메모리 공간의 주소를 계산해내는 과정을 의미한다. 데이터의 위치를 비트 위에 표현하는 방식을 주소지정방식이라 부른다고 앞서 말한 바 있다. 이 단계에서는 해당 명령어의 주소지정방식대로 비트를 해석하여 접근하고자 하는 메모리 주소를 계산하게 된다. 가령 Base + Offset 모드라고 불리는 주소지정방식을 사용하는 명령어의 경우, 레지스터의 번호와 오프셋이 명령어 비트에 표현되어 있다. 그러면 해당 레지스터의 값과 오프셋을 더해서 접근하고자 하는 메모리 주소를 알아내게 된다.
5-5-4. FETCH OPERANDS
명령어 실행에 필요한 데이터를 가져오는 과정이다. 어떤 명령어는 메모리에서 데이터를 가져올 수도 있고, 어떤 명령어는 레지스터에서 데이터를 가져올 수도 있다. 참고로 그렇게 가져오는 데이터를 Source Operand라고 부른다.
5-5-5. EXECUTE
앞선 과정에서 가져온 데이터를 대상으로 필요한 연산을 실제로 실행하는 과정이다. 예를 들어 ADD 명령어는 두 개의 레지스터에서 가져온 데이터를 대상으로 덧셈을 수행할 것이다. 반면 단순히 메모리에 데이터를 쓰거나 메모리로부터 데이터를 읽어오는 명령어의 경우에는 이 단계에서 아무것도 실행하지 않을 것이다. 한편, 기본적으로는 명령어가 순차적으로 실행되지만 조건문이나 함수 호출 등의 경우에는 실행 흐름을 갑자기 바꿔줘야 한다. 그리고 이를 위한 명령어도 따로 존재한다(LC-3의 경우에는 JMP, BRnz 명령어가 이에 해당함). 그런 명령어들의 경우에는 EXECUTE 단계에서 PC 값을 원하는 명령어의 주소로 바꿔주게 된다. 그러면 앞선 FETCH 단계에서 PC를 1만큼 증가시켰던 동작이 완전히 무시되고, 다음 FETCH 단계를 마주했을 때 원하는 명령어를 읽어와서 실행하게 된다.
5-5-6. STORE RESULT
연산 결과를 레지스터 혹은 메모리에 쓰는 과정이다. 메모리에 쓰는 과정의 경우에는, 먼저 쓰고자 하는 데이터를 MDR에 저장하고 데이터를 쓸 위치(메모리 주소)를 MAR에 저장한 뒤 마지막으로 WE 신호를 활성화시켜줄 것이다. STORE RESULT 단계가 마무리되면 앞서 업데이트된 PC의 값을 기반으로 새로운 명령어 사이클이 시작될 것이다.
5-6. 컨트롤 유닛 상태 다이어그램 (FETCH, DECODE)
컨트롤 유닛의 유한 상태 기계를 상태 다이어그램으로 표현하면 대략 다음과 같다. 단 여기서는 FETCH와 DECODE 단계에 해당하는 부분만 간략하게 표시하였으니 완전한 상태 다이어그램을 보려면 책의 부록을 참조하길 바란다.

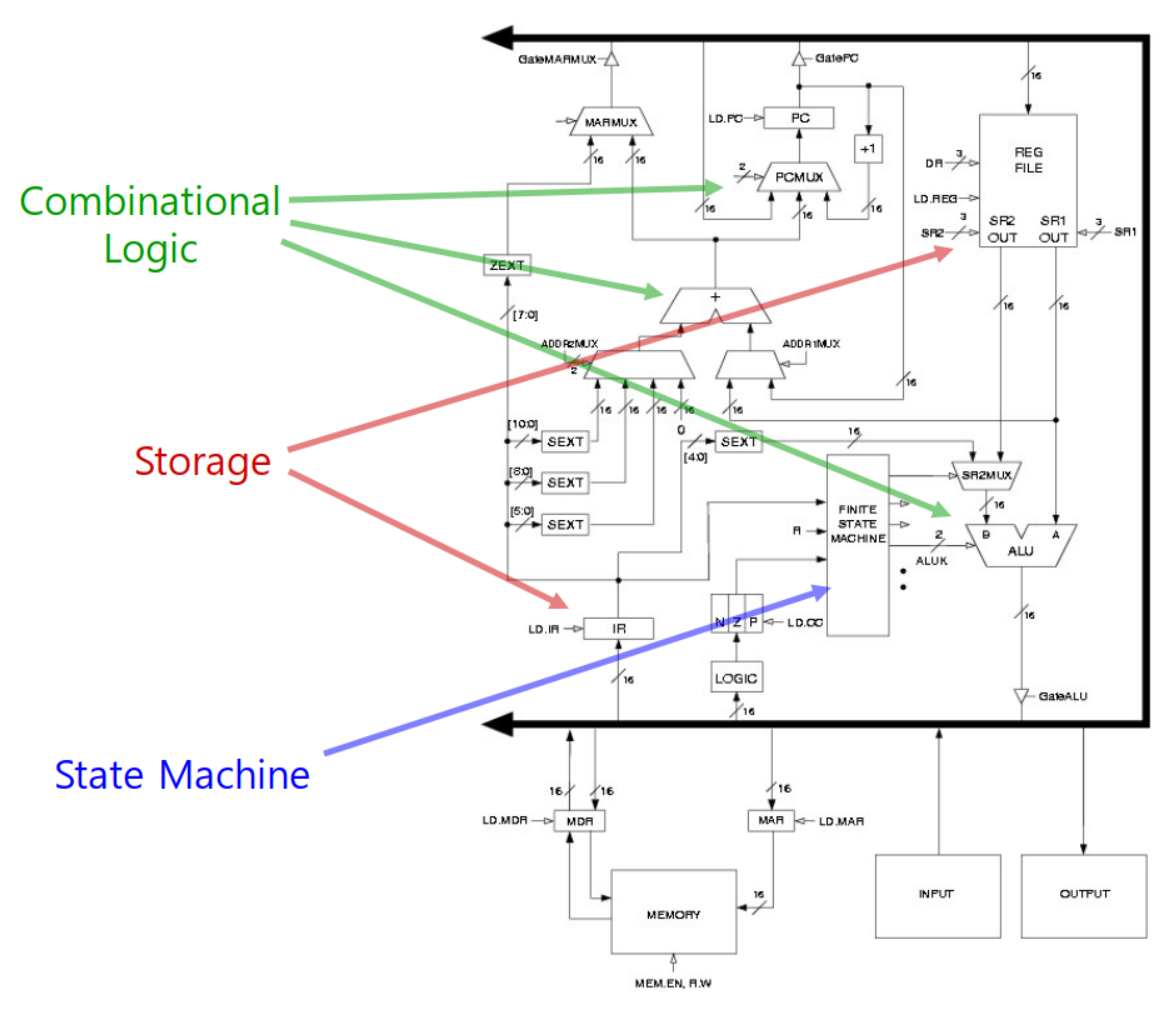
이해를 돕기 위해 간단하게 설명을 보충하자면 다음과 같다. 참고로 GatedXXX는 XXX에 저장된 값이 (글로벌) 버스(모든 장치들이 데이터를 교환하기 위해 사용하는 공통 도선)에 실릴 수 있게 하는 컨트롤 신호이며, LD.XXX은 버스에 실려있는 값이 XXX에 저장될 수 있게 하는 컨트롤 신호로서 WE 신호와 동일하다.
| 단계 | 상태 | 설명 |
| FETCH | 첫 번째 상태 | GatedPC와 LD.MAR 신호가 활성화되어, 현재 PC에 저장된 주소가 MAR에 입력된다. 다만 그 값이 실제로 MAR에 저장되는 건 바로 다음 클락 사이클이 시작될 때다. 또한 PCMUX에는 PC에 1을 더한 값이 선택되게끔 Selector 신호가 입력되고 LD.PC 신호도 활성화되어, 바로 다음 클락 사이클이 시작될 때 PC의 값이 1만큼 증가한다. (클락 신호가 1이 되는 순간 상태 전이가 이뤄지고, 그때 필요한 각 컨트롤 신호가 활성화된다. 그러다가 클락 신호가 0이 되는 순간 MAR과 PC에 저장될 값이 내부에 임시적으로 저장되고, 다시 클락 신호가 1이 되는 순간 그렇게 임시적으로 저장되어 있던 값들이 실제 값으로 저장된다. 이는 MAR과 PC가 마스터-슬레이브 플립플롭 형태로 되어 있기 때문이다.) |
| 두 번째 상태 | PC의 값이 MAR에 저장되고 그 주소에 위치한 데이터가 MDR로 입력된다. 다만 그 값이 실제로 MDR에 저장되는 건 바로 다음 클락 사이클이 시작될 때다. | |
| 세 번째 상태 | GatedMDR(그림에는 표시가 누락되어 있음) 신호가 활성화되어, MDR에 저장된 값이 버스에 실린다. 그리고 LD.IR 신호가 활성화되기 때문에 그렇게 실린 MDR의 값이 IR에 입력된다. 다만 그 값이 실제로 IR에 저장되는 건 바로 다음 클락 사이클이 시작될 때다. | |
| DECODE | 첫 번째 상태 | 명령어가 IR에 저장되고, 그 값이 Decoder로 입력된다. Decoder는 명령어의 opcode를 보고 명령어의 종류를 판단하여 그 결과를 유한 상태 기계에 입력시킨다. 그러면 유한 상태 기계는 현재 상태(DECODE의 첫 번째 상태)와 현재 입력(명령어 종류)을 근거로 다음 상태(명령어 종류에 맞는 EVALUATE ADDRESS의 첫 번째 상태)를 결정하게 된다. |
5-7. 클락이 살아있는 한, 명령어는 계속 실행된다
우리가 작성한 유저 프로그램이 실행되는 동안에는, 클락이 만들어 내는 0과 1의 신호에 따라 컨트롤 유닛의 유한 상태 기계가 상태 전이를 거듭하며 그 프로그램의 코드에 해당하는 명령어를 실행한다. 그런데 만약 아무 유저 프로그램도 실행 중이 아니라면 어떨까? 놀랍게도 이러한 상황에서도 클락의 신호에 따라 어떤 명령어들이 계속해서 실행되는데, 바로 운영체제(Operating System)의 코드에 해당하는 명령어들이다. 즉 OS는 그 자체로 메모리에 언제나 상주하고 있는 하나의 프로그램으로 볼 수 있어서, 컴퓨터를 켜고 가만히 있어도 CPU는 계속해서 OS의 코드를 실행시키는 과정을 똑같은 명령어 사이클을 거치면서 반복하는 것이다.
따라서 클락 신호 발생기의 출력을 0과 AND 시켜서 클락 신호의 입력을 차단한다면, 컨트롤 유닛의 유한 상태 기계는 상태 전이를 더 이상 할 수 없게 되므로 CPU의 동작 전체가 그대로 중단되게 된다. 컴퓨터가 멈추는 것이다.
참고로, 우리가 실행하는 유저 프로그램들의 경우 종료 시 다시 OS나 다른 유저 프로그램이 실행되어야 하기 때문에, 유저 프로그램의 마지막 명령어는 OS 또는 다른 유저 프로그램의 명령어가 위치한 메모리 주소로 PC 값을 바꿔주는 명령어가 되는 것이 보통이다.
'컴퓨터 구조 (Architecture) > 컴퓨터의 개념 및 실습' 카테고리의 다른 글
| [Chapter 7] Assembly Language - 어셈블리어, 어셈블러 (0) | 2020.02.02 |
|---|---|
| [Chapter 5] The LC-3 - ISA를 이해하는 첫 걸음 (11) | 2020.01.26 |
| [Chapter 3] Digital Logic Structures - CPU를 구성하는 기본 부품들 (4) | 2020.01.24 |
| [Chapter 2] Bits, Data Types, and Operations - 데이터의 표현 (4) | 2020.01.13 |
| [Chapter 1] Welcome Abroad - 튜링 머신과 추상화 (10) | 2020.01.12 |