인간의 뇌가 감당할 수 있는 복잡성에는 한계가 있기에, 인간은 여러 추상화 기법들을 발전시켜 나갔다. 대표적으로 데이터 추상화(Data Abstraction)와 함수 추상화(Functional Abstraction)가 있다. 데이터 추상화는 현실에 존재하는 특정 객체의 복잡한 속성을 딱 필요한 것으로만 단순화하여 표현하는 것을 말한다. 가령 '학생'이라는 객체는 이름, 키, 나이, 학번 등의 속성으로 정의할 수 있다. 반면 함수 추상화는 자주 수행되는 특정 동작의 코드들을 하나의 뭉치로 만들고, 필요할 때마다 그것을 재활용하는 것을 말한다. 그 코드 뭉치를 컴퓨터 용어로는 루틴(Routine)이라고 부른다. 가령 문자 하나를 모니터에 출력하게 하는 루틴을 만들어놓고 매번 재활용하는 것이 대표적인 함수 추상화이다.
이번 포스팅에서는 루틴의 개념을 좀 더 깊게 알아볼 것이다. 루틴은 크게 두 가지로 분류할 수 있다. 하나는 운영체제의 코드 내에 존재하는 서비스 루틴(Service Routine), 다른 하나는 사용자가 직접 프로그래밍한 서브 루틴(Sub Routine)이다. 서비스 루틴은 시스템의 루틴이라는 측면에서 시스템 루틴(System Routine)이라고도 부르며, 서비스 루틴을 호출하는 것을 시스템 콜(System Call)이라고 부른다. 그러면 LC-3에서는 서비스 루틴과 서브 루틴을 각각 어떤 메커니즘으로 구현하고 있는지 한 번 알아보도록 하자.
1. 시스템 콜의 존재 이유
먼저, 왜 서비스 루틴과 서브 루틴을 구별했는지부터 알아보자. 어쨌든 둘 다 특정 동작을 수행하는 코드 뭉치인데, 왜 구별했을까? 그 이유를 한 줄로 요약하자면, "하드웨어 수준의 복잡하고 위험한 연산을 프로그래머가 편리하고 안전한 방식으로 수행할 수 있게 하기 위해서"이다. 이게 무슨 말인지 두 가지 측면으로 나눠서 설명하도록 하겠다.
1-1. 프로그래머가 복잡한 전문 지식을 몰라도 된다.
대표적인 서비스 루틴에 해당하는 I/O 연산을, 직접 프로그래머가 서브 루틴으로 작성하여 수행해야 한다고 상상해 보자. 그러기 위해서는 해당 I/O 레지스터들에 대한 지식이 필요할 것이다. 가령 Memory-mapped I/O 방식이라면 해당 I/O 레지스터가 어느 메모리 주소에 맵핑되어 있는지 알아야 한다. 또한 그러한 I/O 레지스터를 가지고 입출력 연산을 수행하기 위해서 어떤 방식으로 해당 I/O 장치와 통신해야 하는지 인터페이스까지 완전히 이해해야 프로그래밍이 가능하다. 그러나 프로그래머들은 이런 것들까지 다 알고 싶어 하지 않는다. 그래서 운영체제 내에 입출력을 위한 코드를 서비스 루틴으로 심어 두고, 프로그래머가 필요할 때 이를 호출하게 하는 것이다. 그러면 프로그래머는 훨씬 더 편리하게 개발에 집중할 수 있다.
1-2. 프로그래머의 실수 혹은 악행을 사전 예방할 수 있다.
프로그래머들의 세계에는 "프로그래머는 무조건 성악설을 믿어야 한다"는 말이 있다. 즉 인간이 어떤 악행도 실수도 저지를 수 있다는 가정 하에 안전하게 코딩해야 한다는 것이다. 시스템 콜의 존재 이유도 이러한 맥락과 관련이 있다. 서비스 루틴에 해당하는 연산들은 보통 I/O 장치와 같이 함부로 건드려서는 안 되는 중요한 하드웨어 장치들에 접근하게 된다. 그런데 그러한 연산을 프로그래머가 작성한 서브 루틴에게 맡기면, 프로그래머가 실수든 악행이든 그러한 장치들을 잘못 건드려서 큰일이 날 수도 있다. 한 유저 프로그램이 나쁜 마음을 먹고 I/O 레지스터의 값을 이상하게 바꾸면, 다른 유저 프로그램들은 입출력이 제대로 동작하지 않을 것이다. 그래서 그런 중요한 하드웨어 장치들에는 특권(Privilege)을 가진 운영체제 프로그램들만 접근할 수 있게끔 제한하는 것이 시스템 콜의 핵심 메커니즘이다. 뒤에서 살펴보겠지만, 일반적인 유저 프로그램과 달리 운영체제의 프로그램들은 특권이라는 것을 가지고 있도록 내부적으로 구현된다. (특권의 구현 방법은 이후에 포스팅할 인터럽트 게시물에서 PSR 레지스터를 설명할 때 소개될 것이다.)
2. LC-3 TRAP 메커니즘
시스템 콜은 보통 다음과 같이 동작한다. 유저 프로그램이 해당 서비스 루틴을 호출하면, 운영체제는 그 서비스 루틴을 실행하여 특정 동작을 수행한 뒤, 제어를 다시 원래의 유저 프로그램에게 돌려준다. LC-3에서는 이러한 시스템 콜을 TRAP이라는 명령어로서 구현하고 있다. LC-3의 TRAP 메커니즘이 어떤 원리로 시스템 콜을 구현하고 있는지 알아보도록 하자.
TRAP 명령어의 비트 구조는 다음과 같다.

2-1. 트랩 벡터 테이블 (Trap Vector Table)
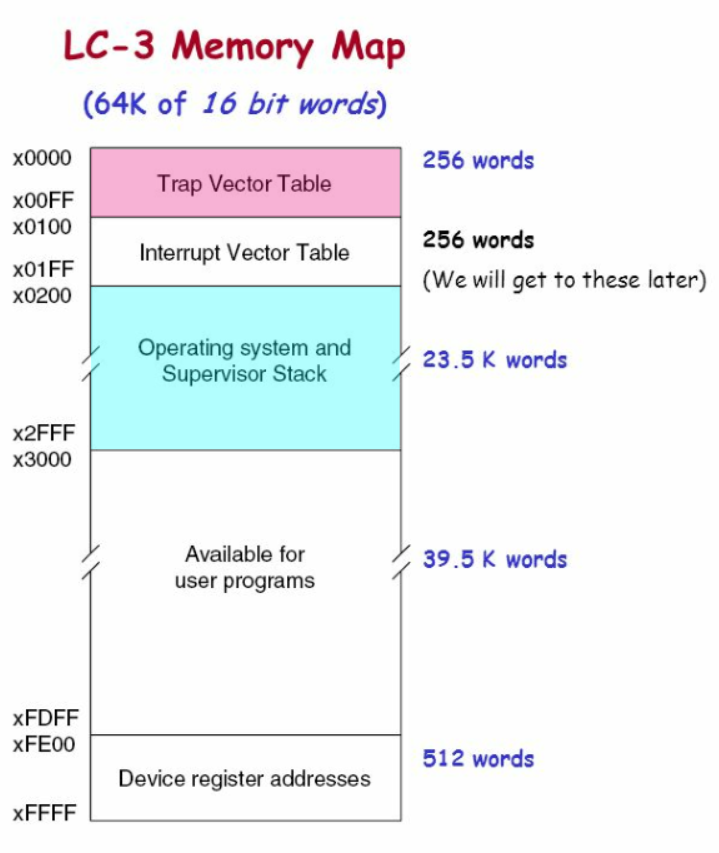
서비스 루틴은 앞서 말했듯 운영체제 코드의 일부이다. 그리고 각 서비스 루틴의 시작 주소는 운영체제 내의 트랩 벡터 테이블(Trap Vector Table)이라는 곳에 저장되어 있다. LC-3의 트랩 벡터 테이블은 메모리[x0000] ~ 메모리[x00FF] 공간에 저장되어 있으므로 총 256개 루틴의 시작 주소를 저장할 수 있다(그러나 LC-3는 6개의 서비스 루틴만 가지고 있음). 참고로 특정 시스템에서는 트랩 벡터 테이블을 시스템 컨트롤 블록(System Control Block)이라고도 부른다. LC-3의 메모리 맵은 다음 그림을 참고하자. 분홍색으로 표시된 부분이 트랩 벡터 테이블이고, 하늘색으로 표시된 부분이 운영체제 코드로서 서비스 루틴들이 위치한 곳이다.
2-2. TRAP 명령어의 실행 동작
2-2-1. 복귀 주소(Return Address) 저장
서비스 루틴을 마치고 다시 원래 프로그램의 실행 흐름으로 돌아오기 위해, 현재의 PC 값을 R7 레지스터에 저장한다. 참고로 이 행위를 수행하는 단계는 FETCH 단계 이후이므로 이미 PC 값이 1만큼 증가한 상태이다. 따라서 나중에 다시 돌아왔을 때는 바로 다음 명령어부터 실행을 재개하게 된다. 다시 돌아온다는 측면에서 그렇게 저장하는 현재 PC 값을 복귀 주소(Return Address)라 부른다.
2-2-2. 서비스 루틴 호출
TRAP 명령어의 하위 8비트로 표현되어 있는 트랩 벡터는, 호출하고자 하는 서비스 루틴의 시작 주소를 저장하고 있는 트랩 벡터 테이블 내 메모리 공간의 주소를 나타낸다. CPU는 내부적으로 트랩 벡터를 메모리 주소에 해당하는 16비트 길이로 Zero Extension 시킨 뒤, 트랩 벡터 테이블로 찾아가 해당 서비스 루틴의 시작 주소를 가져와서 PC에 넣게 된다. 가령 트랩 벡터가 x23이라면 메모리[x0023]에 저장되어 있는 키보드 입력 루틴의 시작 주소를 가져와서 PC에 넣을 것이다. 이로써 CPU의 제어를 운영체제로 넘기면서 서비스 루틴의 실행이 시작된다.
2-2-3. 원래 프로그램의 실행 흐름으로 복귀
해당 서비스 루틴의 마지막 부분에 위치한 명령어는 반드시 JMP R7이다. 즉 R7에 저장되어 있는 복귀 주소를 PC에 저장함으로써 원래 프로그램의 실행 흐름으로 돌아간다. LC-3 어셈블리어에선 JMP R7을 RET라는 기호로 대신 쓸 수 있다. 참고로, 해당 루틴 내에서는 R7의 값을 수정하면 안 된다. 저장되어 있는 복귀 주소가 날아가서 다신 돌아갈 수 없게 되기 때문이다. 루틴 호출과 관련한 레지스터의 백업과 복원 메커니즘에 대해서는 뒤에서 더 자세히 알아보도록 하자.
3. 대표적인 LC-3의 서비스 루틴
그러면 LC-3의 대표적인 서비스 루틴에 해당하는 몇 가지 루틴들의 실제 코드를 한 번 파헤쳐 보자. 직접 차근차근 읽어보며 이해하는 게 가장 도움이 될 것이다. 코드들 중에 특정 레지스터를 백업하고 복원하는 과정에 대해서는 이후에 설명하는 부분을 읽고 나면 이해가 갈 것이다.
3-1. 모니터 출력 루틴 (TRAP x21)
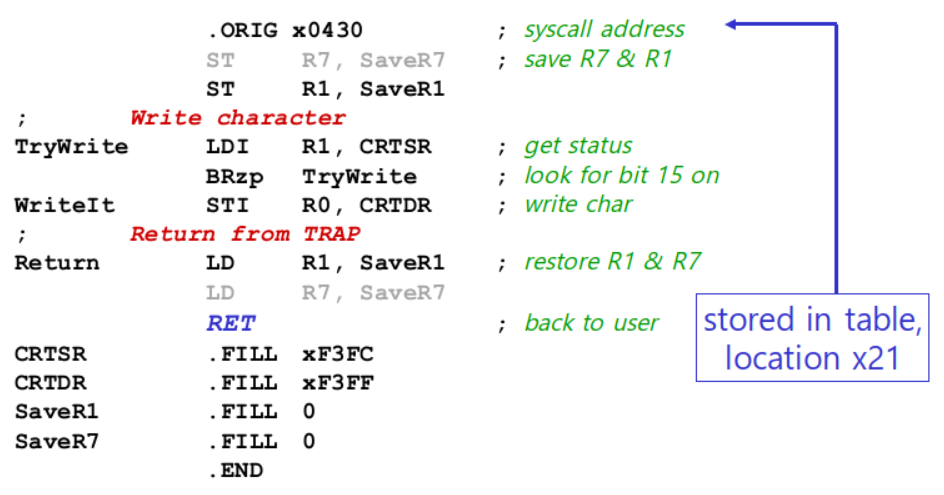
3-2. 키보드 입력 루틴 (TRAP x23)

3-3. 프로그램 HALT 루틴 (TRAP x25)

※ 토막 지식 : Halting 메커니즘
아주 예전에는 프로그램을 Halt 하기 위해 별도로 명령어를 만들어 사용했는데, 사용 빈도수를 고려했을 때 이는 너무 opcode를 낭비하는 것이라 판단되었다. 그래서 많은 현대 컴퓨터들은 RUN latch가 TRAP Halt에 의해 clear 되는 메커니즘을 사용한다. LC-3에서는 RUN latch가 곧 MCR(Machine Control Register)의 bit[15]를 말한다. 그리고 그 MCR은 메모리로부터 주소를 할당받고, 그 주소 값은 xFFFE이다.
4. 레지스터의 백업과 복원 (Saving and Restoring Registers)
서비스 루틴을 호출하든, 서브 루틴을 호출하든, 항상 신경 써야 할 부분이 하나 있다. 바로 레지스터의 값이다. 한 프로그램에서 사용하던 레지스터들의 값은 호출된 루틴 내에서 예상치 못한 방식으로 바꿔버릴 수도 있기 때문이다. 이러한 문제를 예방하기 위해, 다음과 같은 두 가지 방식을 통해 레지스터들의 값을 백업하고 복원하는 과정이 필요하다. 각각에 대해 알아보자.
4-1. Caller-save 방식
특정 루틴을 호출하는 쪽에서 레지스터를 백업하고 복원하는 방식이다. 호출하는 루틴이 무슨 레지스터를 건드릴지 알 수 없기 때문에, 루틴이 끝나고 돌아온 뒤에도 사용할 가능성이 있다고 판단되는 레지스터들은 전부 호출 직전에 백업해 둬야 한다. 그리고 해당 루틴이 종료되어 돌아오면 백업해 두었던 레지스터들의 값을 다시 복원하면 된다. 참고로 레지스터 값의 백업은 보통 특정 메모리 공간에 한다.
4-2. Callee-save 방식
호출되는 루틴 안에서 레지스터를 백업하고 복원하는 방식이다. 호출하는 쪽에서 나중에 무슨 레지스터들을 사용할지 알 수 없기 때문에, 자신이 건드리게 되는 레지스터들을 전부 맨 처음에 백업해 둬야 한다. 그리고 원래 프로그램의 실행 흐름으로 리턴하기 직전에 백업해 두었던 레지스터들의 값을 다시 복원하면 된다. 이 역시 레지스터 값의 백업은 보통 특정 메모리 공간에 한다.
4-3. 루틴 내에서 또 다른 루틴을 호출하는 경우
호출된 루틴 내에서 또 다른 루틴을 호출하는 것은 충분히 가능한 일이다. 이러한 경우, 또 다른 루틴을 호출하기 전에 반드시 R7의 값을 백업해 두어야 한다. 그렇지 않으면 새로운 TRAP 명령에 의해 R7이 수정되므로 돌아갈 위치를 상실하게 되기 때문이다. R7의 값은 TRAP 명령어 자체에 의해 수정되는 것이므로 Callee-save는 불가능하다. 따라서 반드시 Caller-save 방식으로 백업하도록 하는 것이다.
5. 서브 루틴
5-1. 서비스 루틴과의 비교
서브 루틴도 서비스 루틴과 마찬가지로 특정 동작을 수행하는 코드들이 뭉치이다. 그래서 특정 명령어에 의해 호출이 되어 특정 동작을 수행한 뒤 원래 프로그램의 실행 흐름으로 돌아가는 메커니즘은 거의 동일하다. 그러나 서비스 루틴과 달리 서브 루틴은 사람이 직접 프로그래밍한 루틴이어서 운영체제 코드에 속하는 것이 아니라 실행되는 시점에 메모리의 유저 스페이스에 올라간다. 또한 서브 루틴은 서비스 루틴이 가지고 있는 특권을 가지고 있지 못해서 I/O 레지스터와 같은 중요한 하드웨어들을 건드리지 못한다(특권에 대한 자세한 설명은 이후에 포스팅할 인터럽트 게시물 참고). 다음 그림에서 보이는 연두색 영역이 바로 서브 루틴이 위치하는 곳이다.

5-2. JSR/JSRR + RET 명령어
(LC-3 기준) 서비스 루틴을 호출하기 위해 TRAP 명령어가 있다면, 서브 루틴을 호출할 땐 JSR/JSRR 명령어를 사용한다. JSR/JSRR은 TRAP 명령어와 마찬가지로 현재의 PC 값(복귀 주소)를 R7에 저장한 뒤 호출하고자 하는 서브 루틴의 시작 주소로 점프하게 한다. JSR과 JSR은 opcode가 완전히 동일하지만, 호출하고자 하는 서브 루틴의 주소를 계산하는 방법, 즉 주소지정방식만 다르다. JSR은 PC-relative 모드 방식으로 주소를 계산하고, JSRR은 특정 레지스터에 저장된 주소 값을 그대로 사용한다(그래서 접근 가능 주소 범위의 제한이 없음). 물론 서브 루틴 내에서도 원래 프로그램의 실행 흐름으로 돌아갈 때는 RET(= JMP R7) 명령어를 사용한다.
5-3. 입력 파라미터, 출력 파라미터 (Input and Output Parameter)
서브 루틴에 전달하는 변수가 입력 파라미터, 서브 루틴이 결과 값을 저장하는 변수가 출력 파라미터이다. 입력 파라미터의 값은 인자(Argument)라고 부르며, 출력 파라미터의 값은 반환 값(Return Value)이라고 부른다.
5-4. 레지스터의 백업과 복원
서브 루틴도 서비스 루틴과 마찬가지로 레지스터의 백업 및 복원 과정이 필요하다. 일반적으로는 서브 루틴 내에서 Callee-save 방식으로 건드리는 레지스터들을 백업하고 리턴하기 직전에 복원하는 것이 관습이다. 그러면 해당 서브 루틴을 호출하는 입장에서 신경 쓸 거리가 줄어들기 때문이다. 이는 입력 파라미터로 전달되는 레지스터를 건드렸을 때도 해당되는 말이다. 다만 출력 파라미터로 사용하는 레지스터는 굳이 백업과 복원을 할 필요가 없다. 어차피 바깥에서 그것을 쓰는 것이 목적이기 때문이다. 마지막으로, 해당 루틴 내에서 또 다른 루틴을 호출한다면 그 루틴을 호출하기 직전에 R7을 백업해 두었다가 루틴 종료 후 R7을 다시 복원하는 작업이 꼭 필요할 것이다.
5-5. 라이브러리로서의 서브 루틴
앞서 추상화에 대한 이야기를 하면서 함수 추상화를 간단히 소개한 바 있다. 서브 루틴은 인간이 직접 프로그래밍한 코드 뭉치로서, 그것이 만약 유용하고 정말 빈번하게 사용될 만한 기능이라면 '라이브러리(Library)'로서 많은 프로그래머들에게 배포될 수 있다. 이러한 경우 보통은 지적 재산권의 보호를 위해 이미 컴파일이 마무리된 오브젝트 모듈 형태로 배포가 된다. 그런데 특정 라이브러리 루틴을 사용하기 위해서는 그 루틴의 시작 주소를 알고 있어야 한다. 그래서 어셈블러/링커는 보통 EXTERNAL과 같은 심볼을 지원하여, 외부 라이브러리 루틴의 시작 주소를 나타내는 라벨을 사용할 수 있게 한다. 그러면 어셈블러/링커는 해당 라벨이 현재 파일의 심볼 테이블에서 찾을 수 없는 라벨임을 알게 되고 나중에 링킹 할 때 해당 라이브러리 파일의 심볼 테이블에서 그 정보를 찾게 된다.

'컴퓨터 구조 (Architecture) > 컴퓨터의 개념 및 실습' 카테고리의 다른 글
| [Chapter 11] Introduction to Programming in C - 고급 언어의 세계로 (0) | 2020.02.19 |
|---|---|
| [Chapter 10] And, Finally... The Stack - 인터럽트 메커니즘 (0) | 2020.02.09 |
| [Chapter 8] IO - 입력 및 출력 장치 (0) | 2020.02.02 |
| [Chapter 7] Assembly Language - 어셈블리어, 어셈블러 (0) | 2020.02.02 |
| [Chapter 5] The LC-3 - ISA를 이해하는 첫 걸음 (11) | 2020.01.26 |