1. 파이프라인 컨트롤 로직
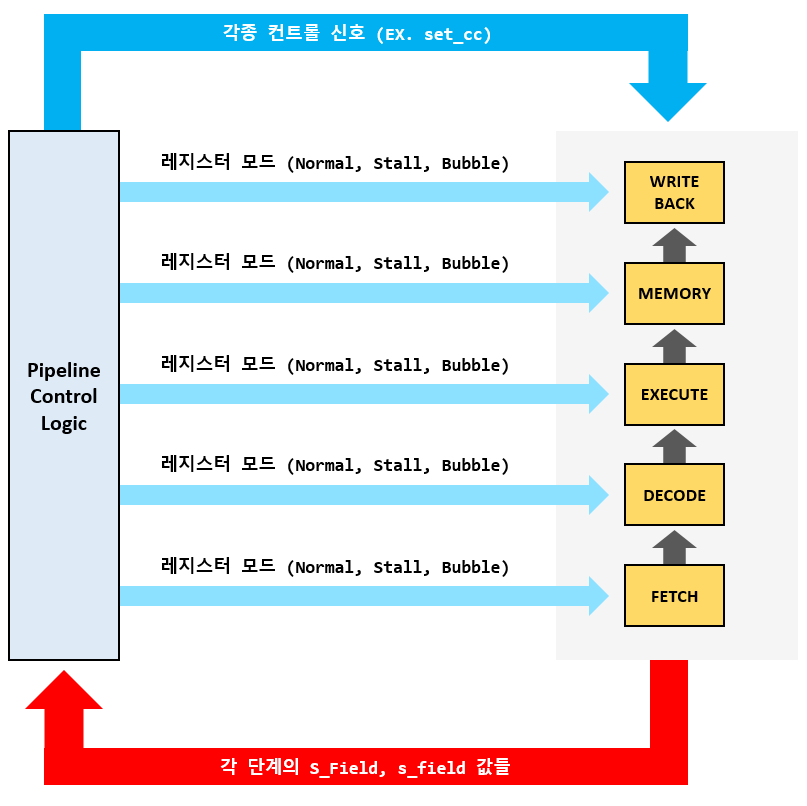
파이프라인 방식으로 구현된 CPU에는 위와 같은 커다란 컨트롤 로직이 존재한다. 해당 컨트롤 로직은 각 단계의 레지스터에 저장된 값들(S_Field)과 각 단계에서 새로 계산되는 값들(s_Field)을 입력으로 받아서, 각종 컨트롤 신호와 각 단계의 레지스터 모드를 결정짓는다. 컨트롤 신호의 예로는 컨디션 코드 레지스터의 값을 변경할지 여부를 나타내는 set_cc가 있다. 그렇다면 레지스터 모드란 무엇을 의미할까?
레지스터 모드로는 Normal, Stall, Bubble이 있다. 특별한 일이 발생하지 않는 이상, 각 단계의 레지스터는 모드는 Normal이다(Stall 신호와 Bubble 신호가 모두 0). 즉, 이전 단계로부터 전달받은 값을 클락의 Rising-edge 때 저장하게 된다. 그러나 이후부터 설명할 특별한 일이 발생하는 경우에는 컨트롤 로직에 의해 특정 단계 레지스터의 모드가 Stall이나 Bubble로 설정될 수 있다. Stall 모드인 경우(Stall 신호만 1) 클락의 Rising-edge가 발생해도 이전 단계로부터 전달받는 값들이 저장되지 않고 무시된다. 즉 한 사이클 동안 가만히 기다리는 것을 의미한다. 그리고 Bubble 모드(Bubble 신호만 1)는 마찬가지로 이전 단계로부터 전달받는 값들을 무시하되, 해당 단계에서 nop 명령어를 실행하도록 한다. 사실상 해당 단계에서 실행 중이던 명령어를 취소하는 것과 같은 이치이다. 이후 설명들을 이해하기 위해 여기서 파이프라인 컨트롤 로직의 역할을 확실히 파악하고 넘어가자.
2. Data Hazard - Stalling
2-1. 기본
파이프라인 방식에서는 앞선 명령어의 실행이 완전히 끝나기도 전에 다음 명령어의 실행이 시작된다. 따라서 Decode 단계에서 읽어 들이는 레지스터의 값이 정확하다고 보장할 수 없다. 이를 해결하는 가장 기본적인 방법은 직전 명령어가 레지스터에 값을 제대로 저장할 때까지 버블을 삽입하면서 현재 단계에서 기다리는 것이다.
2-2. 구현 방식
위에서 말한 방식을 조금 더 구체적으로 설명하자면 다음과 같다. 자신보다 앞선 3개의 명령어에 대해서, 목적지 레지스터 번호가 자신의 소스 레지스터 번호와 매칭 된다면 Fetch와 Decode 단계의 명령어는 그 자리에서 한 사이클 동안 가만히 기다려야 하고(Stall) Execute 단계에는 버블을 삽입해줘야 한다. 3개의 명령어만 검사하는 이유는 앞선 명령어 중에 Write Back 단계를 아직 끝내지 못한 명령어가 3개 존재하기 때문이다. 따라서 버블은 최대 3개까지 연속으로 삽입할 수 있다. 이를 그림으로 나타내면 다음과 같다.

위 그림에서 e_dstE에 주목할 필요가 있다. 왜 이것만 E_dstE가 아니라 e_dstE인 것일까? 그것은 Execute 단계에서 컨디션 코드 레지스터의 값을 바탕으로 dstE의 값을 새로 계산하기 때문이다. 새로 계산하는 이유는 조건 이동 명령어의 경우 조건을 만족하지 않는 경우에 dstE의 값을 0xF로 설정해주기 위함이다. 반대로 조건을 만족하는 경우에는 목적지 레지스터의 번호로 dstE의 값이 설정될 것이다.
3. Data Hazard - Forwarding
3-1. 기본
파이프라인 방식에서는 레지스터의 값이 Write Back 단계가 끝나야 변하지만, 그 값이 계산되는 시점은 Execute 단계 혹은 Memory 단계이다. 이러한 사실을 바탕으로, 레지스터에 저장할 값이 계산되는 시점에 그 값을 바로 다음 명령어에게 전달해줄 수 있다면 그 명령어가 많은 시간을 허비하며 기다리지 않아도 된다. 이러한 방식을 Forwarding이라고 한다. Forwarding 방식을 사용하지 않는다면 앞선 명령어의 Write Back 단계가 끝날 때까지 가만히 기다리면서 클락 사이클을 낭비해야 할 것이다. 그러나 현재 명령어의 Decode 단계가 끝나기 전에 앞선 명령어의 계산 결괏값을 전달받을 수만 있다면, 한 사이클도 낭비하지 않고 바로바로 처리가 가능할 것이다.
3-2. 구현 방식
Forwarding 구현의 핵심은 Decode 단계에서 피연산자의 값을 정확하게 결정하는 것이다. 보통의 경우에는 명령어 비트 배열에 적혀 있는 소스 레지스터의 번호를 레지스터 파일에 입력하여 읽어 들인 값을 피연산자의 값으로 사용한다. 하지만 Forwarding을 사용해야 하는 상황의 조건을 만족하면 앞선 명령어들로부터 전달받는 값을 고려해야 한다. 다음 그림은 Y86-64 파이프라인 CPU의 구조에서 Forwarding과 관련된 부분들을 나타내며, [Sel+Fwd A]와 [Fwd B]라고 이름이 적힌 검은색 박스가 바로 두 개의 피연산자(d_valA, d_valB)를 결정하는 로직이다.

d_valA와 d_valB를 결정하는 로직은 다음과 같다. 먼저 Decode 단계에 존재하는 명령어의 소스 레지스터 번호와 앞선 세 명령어의 목적지 레지스터 번호를 비교한다. 이때 만약 매칭 되는 것이 있다면(Execute → Memory → Write Back 순서로 확인), 그 단계로부터 전달받은 값으로 d_valA와 d_valB를 결정해 준다.

위 로직에서 주목할 점은 세 가지이다. 먼저, 명령어가 call 또는 jXX일 때 왜 D_valP의 값을 피연산자로 사용하는가이다. call 명령어의 경우 복귀 주소를 메모리에 푸시하기 위해 valP의 값을 들고 올라가야 하는데, 파이프라인 레지스터의 절약을 위해서 valP를 저장할 공간으로서 valA의 자리를 빌리는 것이다. 어차피 call 명령어는 valA 자리에 채울 피연산자가 없기 때문이다. 그리고 jXX 명령어는 뒤에서 설명할 브랜치 예측(Branch Prediction)과 관련이 있다. 우리의 파이프라인 방식에서는 jXX 명령어를 실행할 때 우선 조건이 만족됐다고 가정하고 점프를 한다. 그리고 실제로 조건이 만족되었는지 여부는 jXX 명령어가 Memory 단계에 돌입하는 순간 알게 된다. 그때 만약 조건이 만족되지 않았음을 알게 된다면, 지금까지 잘못 실행한 명령어들을 취소하고 jXX 명령어 바로 다음에 위치하는 명령어를 실행시켜야 한다. 이를 위해서는 jXX 명령어 바로 다음에 위치하는 명령어의 주소(= Fetch 단계에 계산한 valP의 값)를 기억하고 있어야 하는데, 그 값을 앞서 말한 것과 같은 이유로 valA 자리를 빌려서 위로 전달하는 것이다.
두 번째로 주목할 부분은 전달받는 필드 값들의 이름이다. 어떤 건 소문자로 시작하고(e_dstE, e_valE, m_valM), 어떤 건 대문자로 시작한다. 앞서 말했듯 대문자로 시작하는 건 파이프라인 레지스터에 저장된 값이고, 소문자로 시작하는 건 CLC에 의해 새로 계산되는 값이다. e_dstE가 E_dstE가 아닌 이유는 Execute 단계에 컨디션 코드 레지스터의 값을 바탕으로 dstE의 값을 새로 계산하기 때문이고(Stalling에서 설명한 이유와 동일), e_valE이 E_valE가 아닌 이유는 Execute 단계에 ALU에 의해서 새로 계산되는 값이기 때문이며, 마지막으로 m_valM이 M_valM이 아닌 이유는 Memory 단계에서 메모리에 의해 읽히는(= 새로 계산되는) 값이기 때문이다. 이 점에 유의하여 로직을 이해하도록 하자.
마지막으로, d_srcA(또는 d_srcB)가 E_dstM과 매칭 되었을 때는 어떤 값으로 d_valA(또는 d_valB)를 결정해줘야 하는가이다. 이러한 문제가 발생하는 이유는 현재 명령어가 Decode 단계에 있을 때 직전 명령어는 아직 Execute 단계이므로 메모리로부터 값을 읽지 못한 상태이기 때문이다. 즉, 직전 명령어가 메모리로부터 값을 읽어서 레지스터에 저장하는 명령어인 경우, 단순히 Forwarding 방식만으로 현재 명령어의 피연산자를 정확하게 결정하지 못한다. 이러한 문제를 Load/Use Hazard라고 부른다. 이에 대한 설명은 이어지는 설명을 참고하자.
3-3. Load/Use Hazard
앞서 언급한 Load/Use Hazard를 해결하는 방법은 단순하다. Load/Use Hazard 상황의 조건이 만족되면, 현재 Fetch와 Decode 단계에 있는 명령어는 가만히 있는 채로 Execute 단계로 버블을 하나만 흘려보내주면 된다. 이를 그림으로 나타내면 다음과 같다. 이와 같은 방식으로 한 사이클만 처리하면, 다음 사이클부터는 위에서 설명한 Forwarding의 원칙에 근거하여 문제없이 동작하게 된다.

4. Control Hazard - Branch Prediction
4-1. 기본
우리의 파이프라인 방식에서는 Control Hazard를 Branch Prediction 방식으로 해결한다. 특히 그중에서도 조건이 만족된다고 예측하는 방식(Predict-taken)을 채택한다. 즉 조건 분기 명령어가 Fetch 단계에 돌입하는 순간에는 조건이 만족됐는지 알 방법이 없으므로 일단 조건이 만족된다고 가정해서 점프를 하고, 나중에 조건이 만족되지 않았음을 알게 되면 잘못 실행했던 몇 개의 명령어를 취소한 뒤 올바른 명령어를 실행하는 것이다. 실제로 조건 분기 명령어의 60퍼센트는 조건을 만족한다는 것이 알려져 있기 때문에, 무조건 버블을 삽입하며 기다리는 것보다는 이 방식이 성능적으로 더 좋다고 평가할 수 있다.
4-2. 구현 방식
Predict-taken 구현의 핵심은 예측이 틀린 경우에 잘못 실행된 명령어들을 어떻게 취소하는가이다. 예측이 맞는 경우에는 아무 문제없이 동작하므로 별도로 고려할 것이 없기 때문이다. 예측이 틀린 경우를 판단하는 방법은 이렇다. Execute 단계에 돌입하면 직전 명령어의 실행 결과로 세팅된 컨디션 코드 레지스터의 값과 E_icode의 값을 바탕으로 조건 만족 여부(e_Cnd)를 계산하는 것이다. 다음 그림은 Y86-64 파이프라인 CPU의 구조에서 해당 내용과 관련된 부분을 나타낸다.
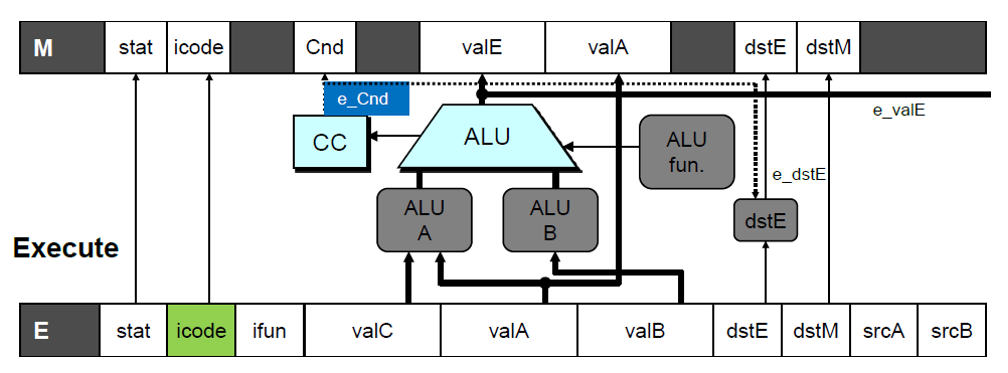
이렇게 Execute 단계에서 계산한 e_Cnd의 값을 바탕으로 조건이 만족되지 않았음을 파악하게 되면, 파이프라인 컨트롤 로직은 Decode와 Execute 단계 레지스터에 버블을 삽입하게 된다. 그러면 다음 사이클에는 Decode와 Execute 단계에서 nop 명령어가 실행되므로 사실상 잘못 실행되었던 두 개의 명령어는 취소가 된다(Side Effect 없음). 그리고 Memory 단계에 돌입하면서 전달받는 M_Cnd의 값과 M_valA의 값을 바탕으로 Fetch 단계에서 올바른 명령어를 실행하게 된다. 이 내용을 그림으로 나타내면 다음과 같다.

5. Control Hazard - Return
5-1. 기본
ret 명령어의 경우 예측이라는 것을 할 수가 없다. 따라서 일단 다음 명령어들을 실행시키다가 나중에 취소시키거나, 단순히 버블을 삽입하며 기다리는 방식을 사용해야 한다. 이 경우 Branch Prediction과 달리 전자의 방식이 아무런 이득이 없으므로 후자의 방식을 택한다. 즉, 복귀 주소를 메모리에서 팝 하여 올바른 명령어를 실행할 수 있을 때까지 버블을 삽입하며 기다리는 것이다.
5-2. 구현 방식
전/전전/전전전 명령어가 ret 명령어에 해당하는 경우, Fetch 단계의 명령어는 가만히 있고 Decode 단계에 버블을 흘려보내면 된다. 쉽게 말해서 앞서 있는 ret 명령어가 복귀 주소를 메모리에서 제대로 팝 하여 Write Back 단계에 돌입할 때까지는 다음 명령어 실행을 보류하는 것이다. ret 명령어가 Write Back 단계에 돌입하면 W_valM의 값을 바탕으로 올바른 명령어를 실행할 수 있기 때문이다. 따라서 이 방식에서는 연속적인 세 개의 버블을 삽입하게 되어 어쩔 수 없이 세 사이클이 낭비된다. 다음 그림들은 해당 내용과 관련된 Y86-64 파이프라인 CPU의 구조와 동작 방식을 나타낸다.
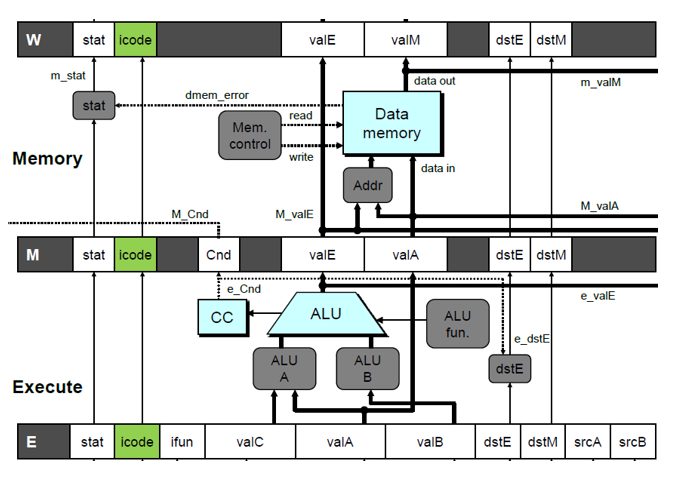

6. Special Control Cases
6-1. Control Cases Summary
지금까지 이야기한 세 가지의 이벤트가 발생하는 조건과 그때 설정되어야 하는 각 파이프라인 레지스터의 모드를 정리하면 다음과 같다.


6-2. Special Control Case
그런데 위와 같은 이벤트가 2개 이상 겹쳐서 발생하면 파이프라인 컨트롤 로직이 각 파이프라인 레지스터의 모드를 어떻게 설정할지에 대한 충돌이 발생하게 된다. 대표적으로 아래의 두 경우가 있는데, 각각의 경우에 파이프라인 레지스터의 모드들을 어떻게 설정해줘야 하는지 알아보도록 하자.
6-2-1. Control Combination A

6-2-2. Control Combination B


'컴퓨터 구조 (Architecture) > CSAPP' 카테고리의 다른 글
| [CSAPP] Pipelining - Performance (0) | 2020.03.15 |
|---|---|
| [CSAPP] Pipelining - Wrap up (0) | 2020.03.14 |
| [CSAPP] Pipelining - Part 1 (0) | 2020.03.11 |
| [CSAPP] Pipelining - Introduction (0) | 2020.03.10 |
| [CSAPP] Sequential Implementation (0) | 2020.03.09 |