1. Cache Memory
1-1 기본
캐시 메모리(Cache Memory)는 DRAM보다 작지만 속도가 빠른 SRAM을 기반으로 만들어진 메모리 소자를 말한다. 메인 메모리의 데이터들은 블록이라는 단위로 나뉘며, 캐시 메모리는 메인 메모리에서 높은 빈도로 접근되는 블록들을 저장한다. 그리고 CPU는 메모리 참조가 필요할 때마다 메인 메모리보다 더 가깝고 접근 속도가 빠른 캐시 메모리를 먼저 확인한다. 이러한 원리로 CPU와 DRAM의 직접적인 통신을 최소화함으로써 메모리 참조의 효율을 높일 수 있다. 캐시 메모리는 DRAM과 SRAM으로 이뤄진 메모리 기술(Memory Technology)에 참조의 지역성(Locality)을 결합하여 탄생시킨 기술적 산물이라고 볼 수 있다.
참고로 캐시 메모리는 여러 층으로 이뤄질 수도 있다. 실제로 인텔의 몇몇 CPU는 메모리 계층이 L1, L2, L3, 그리고 메인 메모리로 이뤄져 있다. 즉, L1을 먼저 확인하고, 없으면 L2를 확인하며, 여기서도 없으면 L3를 확인하고, 그래도 없으면 메인 메모리에 찾아가는 방식이다.
1-2. CPU와 캐시 메모리의 통신 구조 (인터페이스)
아래 그림은 지난 포스팅에서 보여준 기본적인 CPU와 메모리의 통신 구조에 캐시 메모리까지 더해진 형태를 보여준다. 캐시 메모리가 없다면 시스템 버스와 메모리 버스를 거쳐서 메인 메모리에 직접 찾아가야 하지만, 캐시 메모리를 갖춘 CPU는 메모리 참조가 필요할 때 가까운 곳에 위치한 캐시 메모리에 먼저 접근하도록 설계가 된다. 즉, 메모리 참조 시 메모리 주소를 곧바로 시스템 버스에 싣는 게 아니라 캐시 메모리에 먼저 입력하도록 함으로써 하드웨어 수준에서 캐시 메모리 메커니즘을 구현하는 것이다. 따라서 메모리 참조 성능은 개선되지만 기능적으로는 프로그래머가 보기에 캐시 메모리가 있든 없든 똑같다. 하드웨어 내부적으로 메모리 참조를 추상화한 것이다.

1-3. 일반적인 캐시 메모리의 구조 (S, E, B)
다음은 캐시 메모리의 일반적인 구조를 나타낸다. 캐시 메모리는 S개의 집합(Set)으로 이뤄져 있고, 각 집합은 E개의 캐시 라인(Cache Line)을 저장한다. 각 캐시 라인은 메인 메모리에서 가져오는 블록(Block) 하나와 그것이 유효한지를 나타내는 유효 비트(Valid Bit), 그리고 동일한 집합에 들어올 수 있는 다른 블록들과 구별하기 위한 태그(Tag)를 저장한다. 따라서 메인 메모리의 각 블록이 B바이트라고 할 때, 캐시 메모리의 총사이즈는 (S x E x B) 바이트가 된다. 참고로 E = 1이면 Direct-Mapped Cache, E > 1이면 E-way Set Associative Cache라고 부른다.

이때 메인 메모리의 각 블록은 캐시 메모리의 특정 집합에만 들어갈 수 있도록 되어 있다. 예를 들면 메인 메모리의 256번째 블록은 캐시 메모리의 4번째 집합에만 들어갈 수 있는 것이다. 왜 이런 규칙을 정한 것일까? CPU가 참조하고자 하는 메모리의 주소를 캐시 메모리에 입력하면, 캐시 메모리는 그 주소에 해당하는 메인 메모리의 블록을 자신이 가지고 있는지 확인해야 한다. 그런데 메인 메모리의 각 블록이 캐시 메모리의 어디에든 들어갈 수 있다면, 캐시 메모리는 CPU로부터 메모리 참조를 요청받을 때마다 해당 블록을 찾는 데 상당히 많은 시간이 걸린다. 캐시 메모리 내 블록들을 전부 정렬하거나, 일일이 뒤져야 하기 때문이다. 따라서 메인 메모리의 각 블록은 자신의 주소에 따라 캐시 메모리의 특정 집합에만 들어갈 수 있도록 약속한다. 이렇게 하면 캐시 메모리는 입력받은 메모리 주소를 바탕으로 요청된 블록이 위치할 수 있는 집합에서만 탐색을 진행하면 된다. 각 집합 내 블록의 개수는 유한하기 때문에 블록 탐색 시간 복잡도는 O(1)이 된다. 이는 해싱(Hashing) 알고리즘을 적용한 사례라고 할 수 있다.
이러한 맥락에서 캐시 라인에 저장되는 태그(Tag)의 정체를 알아보자. 설명을 위해 CPU로부터 입력받는 메모리 주소가 m(= t+s+b)바이트로 표현되고, 메모리의 총사이즈는 M(= 2^m) 바이트라고 가정하자. 그러면 메모리 주소는 다음과 같은 구조로 나눠서 생각해볼 수 있다.

여기서 s와 b는 캐시 메모리 집합의 개수 S와 블록의 사이즈 B에 대하여 S=2^s와 B=2^b를 만족하는 값이다. 이때 메인 메모리의 각 블록의 사이즈가 B(= 2^b) 바이트이므로 메인 메모리는 총 M/B개의 블록으로 이뤄졌다고 볼 수 있다. 그러면 m비트의 메모리 주소에서 상위 (m-b) 비트가 블록의 위치를 지정하며, 하위 b비트는 해당 블록 내 바이트 오프셋을 나타낸다고 생각할 수 있다. 그리고 상위 (m-b) 비트 중 하위 s비트가 동일한 블록들은 동일한 집합에 들어가게 된다. 이때 동일한 집합에 들어갈 수 있는 여러 개의 블록들을 구별해주는 비트가 바로 상위 t비트인 것이다. 이 값이 곧 캐시 라인에 저장되는 태그(Tag)이다.
2. Cache Read
2-1. 기본
CPU가 참조하고자 하는 메모리의 주소를 캐시 메모리에 입력하면, 캐시 메모리는 다음과 같은 절차로 요청된 블록을 탐색한다. 먼저, 입력되는 메모리 주소의 s비트를 바탕으로 요청된 블록이 위치할 수 있는 집합을 찾아간다. 그리고 그곳에서 요청된 블록의 태그(= 입력되는 메모리 주소의 상위 t비트 값)와 동일한 태그를 가지는 유효한(유효 비트 = 1) 캐시 라인이 존재하는지 탐색한다(시간 복잡도 = O(1)). 만약 발견된다면 캐시 히트(Hit)이고, 발견되지 않으면 캐시 미스(Miss)이다.

캐시 히트인 경우, 입력되는 메모리 주소의 하위 b비트와 읽을 바이트의 개수를 나타내는 컨트롤 신호 정보를 바탕으로 해당 블록 내에서 요청된 바이트 배열을 반환한다. 반면 캐시 미스인 경우, 해당 블록을 메인 메모리에서 가져온 뒤 캐시 히트인 경우와 마찬가지로 요청된 바이트 배열을 반환한다. 만약 해당 블록이 들어가야 할 집합이 이미 꽉 차 있다면, 정해진 어떤 기준에 따라 해당 집합에서 하나의 블록을 쫓아내야 한다. 이때 그 기준을 정의하는 것이 바로 Replacement Policy이다. 대표적인 Replacement Policy로는 임의의 블록을 쫓아내는 random 방식, 그리고 가장 예전에 참조되었던 블록을 쫓아내는 LRU(Least Recently Used) 방식이 있다.
2-2. Direct-Mapped Cache 예시 (E = 1)
다음은 각 집합에 블록이 1개만 들어갈 수 있는 캐시 메모리에서 읽기 작업을 수행하는 예시이다.

그리고 다음은 2차원 배열의 접근 순서에 따라서 캐시 히트 확률이 달라지는 것을 보여주는 예시이다. 캐시 메모리에 집합이 8개 존재하고 각 집합은 32바이트 크기의 블록을 1개씩 저장할 수 있다고 가정하자. 그러면 각 배열 요소의 크기는 8바이트이므로(double) 한 캐시 라인에는 4개의 배열 요소를 저장할 수 있다. 아래의 오른쪽 그림은 각 배열 요소가 들어갈 수 있는 집합의 위치를 나타낸다. 이때, 2차원 배열의 요소들을 row 순서로 접근하면 캐시 히트 확률이 75%가 된다는 것을 알 수 있다. a[0][0], a[0][1], a[0][2], a[0][3] 순서로 접근하면 a[0][0]에 접근할 때만 캐시 미스가 발생하고, 나머지 세 경우에서는 캐시 히트가 발생하기 때문이다. 반면, 2차원 배열의 요소들을 column 순서로 접근하면 캐시 히트 확률은 0%가 된다. a[0][0], a[1][0], a[2][0], a[3][0] 순서로 접근하면 매번 캐시 라인을 교체해야 하기 때문이다.

2-3. E-way Set Associative Cache 예시 (E > 1)
다음은 각 집합에 블록이 2개 들어갈 수 있는 캐시 메모리에서 읽기 작업을 수행하는 예시이다.

그리고 다음은 위에서 다뤘던 동일한 2차원 배열에 대해 접근 순서에 따라 캐시 히트 확률이 어떻게 달라지는지 보여주는 예시이다. 이번에는 캐시 메모리에 집합이 4개 존재하고 각 집합은 32바이트 크기의 블록을 2개씩 저장할 수 있다고 하자. 아래의 그림은 각 배열 요소가 들어갈 수 있는 집합의 위치를 나타낸다. 이때, 2차원 배열의 요소들을 row 순서로 접근하면 마찬가지 이유로 캐시 히트 확률은 75%가 된다. a[0][0], a[0][1], a[0][2], a[0][3] 순서로 접근하면 a[0][0]에 접근할 때만 캐시 미스가 발생하고, 나머지 세 경우에서는 캐시 히트가 발생하기 때문이다. 또한 2차원 배열의 요소들을 column 순서로 접근하면 마찬가지 이유로 캐시 히트 확률은 0%가 된다. a[0][0], a[1][0], a[2][0], a[3][0] 순서로 접근하면 매번 캐시 라인을 교체해야 하기 때문이다.

3. Cache Write
읽기 작업과 달리 쓰기 작업은 고려해야 할 점이 조금 있다. 이와 관련하여, 쓰기 작업을 수행하고자 하는 블록이 캐시에 존재하는 경우(캐시 히트)와 캐시에 존재하지 않는 경우(캐시 미스)로 나눠서 고려해야 할 점에 대해 알아보도록 하자.
3-1. 쓰기 작업을 수행할 블록이 캐시에 존재하는 경우 (Write Hit)
이러한 경우, 캐시 메모리의 내용만 수정할지 아니면 메인 메모리의 내용도 수정할지 결정해줘야 한다. 이때 캐시 메모리의 블록을 수정해주고 곧바로 해당되는 메인 메모리의 블록도 수정해주는 방식을 Write-through라고 한다. 반면, 일단은 캐시의 블록만 수정해주고 해당 블록의 내용은 나중에 캐시 메모리에서 쫓겨날 때 메인 메모리에 반영해주는 방식을 Write-back이라고 한다. Write-back 방식의 경우 해당 캐시 라인의 블록이 메인 메모리의 블록과 다르다는 것을 표시하기 위한 Dirty Bit가 필요하다.
3-2. 쓰기 작업을 수행할 블록이 캐시에 없는 경우 (Write Miss)
이러한 경우, 메인 메모리의 내용만 수정할지 아니면 수정된 블록을 캐시 메모리로 가져오는 것까지 할지 결정해줘야 한다. 이때 메인 메모리의 블록만 수정해주는 방식을 No-write-allocate라고 한다. 반면, 메인 메모리의 블록을 수정해준 다음에 해당 블록을 캐시 메모리로 로드하여 캐시 라인을 갱신해주는 방식을 Write-allocate라고 한다. Write-allocate 방식의 경우, 해당 메모리 주소를 대상으로 쓰기 작업이 반복되는 경우가 많을 때 상당히 효율적이다. 참고로 No-write-allocate 방식은 Write-through 방식과 함께 사용이 되고, Write-allocate 방식은 Write-back 방식과 함께 사용되는 것이 일반적이다.
4. Cache Performance
4-1. 성능 척도
Miss Rate란 캐시 미스가 발생할 확률을 의미하며, 캐시 미스 횟수를 메모리 참조 횟수로 나누면 얻을 수 있다. 일반적으로 L1 캐시는 3~10%의 Miss Rate를, L2는 그것보다 더 작은(1% 미만) Miss Rate를 보이는 경향이 있다. 이는 해당 캐시 메모리 사이즈 등의 요인에 의해 결정이 될 것이다. 그런데 여기서 하나 의문이 있다. 왜 Hit Rate가 아니라 Miss Rate를 다루는 것일까? 이는 캐시 히트와 캐시 미스 시에 소요되는 시간이 굉장히 차이 나기 때문이다. 어림만 잡아도 캐시 미스 시에 소요되는 시간 캐시 히트 시에 소요되는 시간보다 100배는 더 길다. 캐시 미스 시에는 다음 단계의 메모리 소자에 찾아가서 다시 탐색해야 하기 때문이다. 이러한 이유로, Miss Rate의 작은 변화만으로도 평균적인 메모리 참조 시간이 굉장히 달라지기 때문에 Hit Rate가 아닌 Miss Rate를 더 중점적으로 다루게 된다.
Hit Time이란 캐시 메모리의 캐시 라인을 CPU에게 전달하는 데까지 걸리는 시간을 의미한다. 여기에는 해당 캐시 라인이 캐시 메모리에 있는지 탐색하는 데 걸리는 시간도 포함된다. 일반적으로 L1 캐시는 1~2 사이클, L2 캐시는 5~20 사이클이 소요된다.
Miss Penalty는 캐시 미스로 인해 추가로 소요되는 시간을 의미한다. 즉, 캐시 미스가 발생하여 다음 단계의 메모리 소자로 찾아서 탐색을 진행하여 캐시 라인을 가져오는 데 걸리는 시간에 해당한다. 여기에 Hit Time을 더하면 실제로 메모리 참조에 걸리는 시간을 계산할 수 있다. 일반적으로 캐시에서 미스가 발생하여 메인 메모리에 찾아가게 되는 경우 Miss Penalty는 대략 50~200 사이클이다. Hit Time에 비해서 상당히 긴 시간이 소요된다는 것을 알 수 있다. Miss Rate를 중점적으로 다루는 이유가 여기에 있다.
4-2. 캐시 메모리 친화적인 코드를 작성하는 요령
캐시 메모리의 동작 방식을 이해했다면, 어떻게 코딩을 해야 캐시 메모리를 최적으로 활용할 수 있을지 생각해 보자. 우선, 가장 중요한 것은 흔한 경우(Common Case)를 빠르게 만드는 것이다. 흔한 경우의 대표적인 예시로는 자주 호출되는 함수에 존재하는 반복문이다. 캐시 메모리는 흔한 경우에 대해 아주 빠르게 동작하게끔 설계된 것이기 때문이다. 다음으로, 반복문 내에서도 캐시 미스를 최소화하는 것이다. 앞서 알아보았듯이, 같은 기능을 하는 코드여도 2차원 배열의 접근 순서에 따라 캐시 히트 확률이 현저히 달라질 수 있다. 따라서 최대한 변수의 반복적인 참조를 지향하여 시간적 지역성을 확보하고, (연속적으로 할당된 데이터의) 순차적인 참조를 통해 공간적 지역성을 얻는 것이 중요하다. 캐시 메모리 기술이 우리가 지금까지 논의했던 지역성이라는 정성적인 아이디어를 구체화하고 정량화해주는 모습을 볼 수 있는 것이다.
4-3. Miss Rate에 영향을 주는 요인
결국 캐시 메모리의 성능을 결정짓는 핵심적인 척도는 Miss Rate이다. 그렇다면 Miss Rate에 영향을 주는 요인들로는 무엇이 있을까? 크게 세 가지 요인에 따라서 Miss Rate가 어떻게 변하는지 알아볼 것이다. 바로 Cache Size, Block Size, 그리고 Set Associativity이다.
먼저, 다른 요인들이 일정하다고 가정할 때 Cache Size가 커질수록 Miss Rate는 감소한다. 더 많은 블록들이 캐시 메모리에 들어갈 수 있게 되어 시간적 지역성을 더 얻기 때문이다. 그렇다면 Cache Size가 일정할 때 다른 요인들의 변화에 따라 Miss Rate는 어떻게 변하는지 한 번 알아보자.
Cache Size가 일정할 때 Block Size의 변화에 따른 Miss Rate의 변화를 생각해 보자. Block Size가 크다면 한 번에 메인 메모리에서 가져오는 데이터의 사이즈가 크다는 것이므로, 공간적 지역성을 더 얻는다. 반면 Block Size가 작다면, 더 과거에 참조된 블록들까지도 캐시 메모리에 저장해둘 수 있으므로 시간적 지역성을 더 얻는다. 따라서 Block Size가 너무 커서도 안 되고, 너무 작아서도 안 된다. 중간 지점의 Block Size에서 Miss Rate는 최솟값을 가질 것이다.
다음으로, Cache Size가 일정할 때 Set Associativity의 변화에 따른 Miss Rate의 변화를 생각해 보자. Set Associativity가 커질수록 집합의 총개수는 줄어들고 각 집합의 캐시 라인 개수가 증가한다. 즉, Fully Associative에 가까워지는 것이다. 이는 곧 메인 메모리의 각 블록이 캐시 메모리에서 들어갈 수 있는 자리가 많아진다는 것을 의미한다. 이렇게 되면 충돌 미스(Conflict Miss)가 감소하고 캐시 메모리 빈 공간의 활용도가 높아지므로 Miss Rate는 감소한다. 그러나 캐시 메모리에서 요청된 블록을 탐색하는 데 걸리는 시간이 증가하므로 Hit Time은 증가한다. 반면 Set Associativity가 감소하면 Miss Rate는 증가해도 탐색 시간이 줄어드므로 Hit Time은 감소할 것이다. 이는 바로 이어서 설명할 L1, L2, L3 캐시의 차이와 관련이 있다.
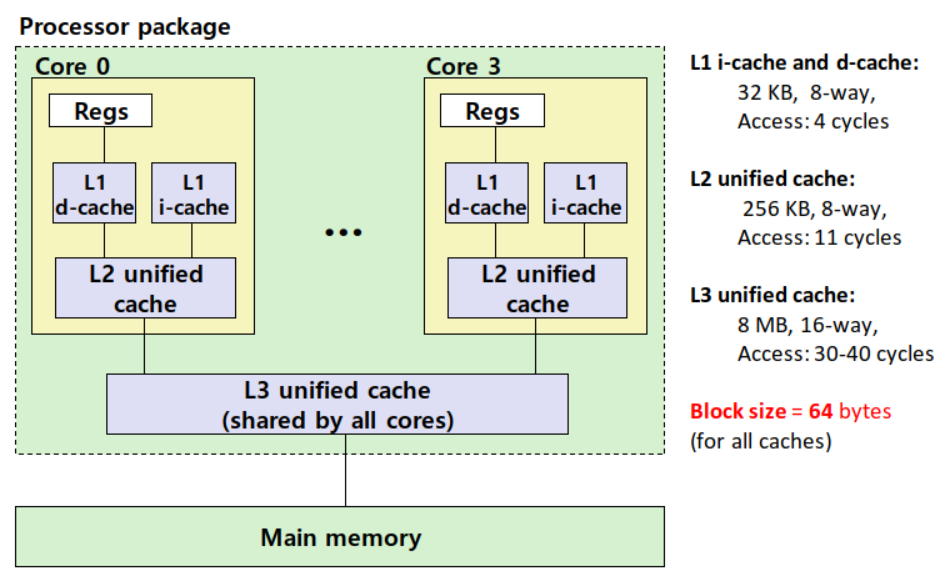
4-4. Intel Core i7 Cache Hierarchy
다음은 인텔 Core i7 CPU의 캐시 메모리 계층 구조를 나타낸다. 메인 메모리 이전에 세 단계의 캐시 메모리(L1, L2, L3)가 존재하는 것을 볼 수 있다. 이때, CPU에 가까울수록(L1으로 갈수록) Cache Size와 Set Associativity가 작고, 메인 메모리에 가까울수록(L3로 갈수록) Cache Size와 Set Associativity가 크다는 것을 관찰할 수 있다. 이는 CPU에 가까운 메모리 계층일수록 Hit Time을 줄이는 것이 중요하고, 메인 메모리에 가까운 메모리 계층일수록 Miss Rate를 줄이는 것이 중요하기 때문이다.
'컴퓨터 구조 (Architecture) > CSAPP' 카테고리의 다른 글
| [CSAPP] Exceptional Control Flow (10) | 2020.03.24 |
|---|---|
| [CSAPP] Linking (13) | 2020.03.22 |
| [CSAPP] Memory Hierarchy (6) | 2020.03.17 |
| [CSAPP] Pipelining - Performance (0) | 2020.03.15 |
| [CSAPP] Pipelining - Wrap up (0) | 2020.03.14 |