1. 서론
인덱스(Index), 즉 색인이라는 말을 책에서 본 경험이 있을 것이다. 원하는 내용을 쉽게 찾을 수 있도록 책 뒤편에 마련해둔 테이블이 바로 그것이다. 여기에는 책에 서술되어 있는 내용들의 주요 키워드들이 사전 순서로 나열되어 있고, 각각의 키워드에 대하여 해당 내용이 서술되어 있는 페이지의 번호가 적혀 있다. 이를 통해 우리는 원하는 내용이 서술되어 있는 페이지로 단번에 찾아갈 수 있다. 데이터베이스에서의 인덱스도 개념적으로는 이것과 완전히 동일하다. 인덱스는 테이블의 레코드 개수가 많을 때도 효율적으로 검색을 수행할 수 있도록 도와주는 일종의 테이블이다. 이제 본격적으로 인덱스에 대해 한 번 알아보자.
▼ 일반적인 책의 인덱스

2. 인덱스의 개념
데이터베이스의 인덱스(Index)란 관계형 데이터베이스에서 테이블 내에 존재하는 수많은 레코드들 가운데 원하는 레코드를 빠르게 검색할 수 있도록 도와주는 또 다른 종류의 테이블이다. 인덱스는 해당 테이블에서 레코드의 주솟값과 검색 대상 필드(들)의 값들을 추출하여 만드는 부분 테이블이기 때문에, 원래의 테이블보다는 훨씬 더 적은 용량을 차지하게 된다. 인덱스는 단순히 검색 등과 같은 쿼리의 성능을 향상시키는 별도의 자료구조일 뿐, 쿼리의 수행 결과 자체에는 아무런 영향을 주지 않는다. 책 뒤편에 마련해 두는 색인 표를 떠올리면 조금 더 수월하게 이해할 수 있을 것이다.
인덱스가 없다면 특정 필드(들)의 값을 기준으로 검색을 수행할 때 모든 레코드들을 일일이 뒤져야 할 것이다(Full Scan). 그러나 인덱스를 사용한다면 얘기는 달라진다. 인덱스에서 검색 대상 필드(들)의 값에 해당하는 레코드들의 주솟값을 빠르게 찾아내고 나면, 그 주솟값들을 토대로 원래의 테이블에서 원하는 레코드들을 빠르게 찾아낼 수 있다. 어떻게 이것이 가능할까? 그러면 이번에는 인덱스의 동작 원리에 대해 조금 더 자세히 알아보도록 하자.
3. 인덱스의 동작 원리 (검색 시)
앞서 말했듯이, 인덱스가 없다면 검색을 수행할 때마다 테이블 내 모든 레코드들을 일일이 뒤져야 한다(Full Scan). 이는 검색의 효율을 상당히 떨어뜨린다. 그렇다면 인덱스가 있을 때는 검색을 어떻게 수행할까? 이에 대해 한 번 알아보자.
인덱스는 다음과 같은 두 가지 특징을 가지고 있다.
- 기본적으로 인덱스는 검색 대상 필드(들)의 값을 기준으로 이미 정렬이 되어 있다. 마치 책의 색인 표가 키워드들을 사전 순으로 나열한 것처럼 말이다. 따라서 해당 필드의 값을 토대로 인덱스에서 검색을 수행하는 것은 속도가 상당히 빠르다. 이는 (뒤에서 알아보겠지만) 인덱스가 B+Tree와 같은 자료 구조로 구현되어 있기 때문이다. 이 경우, 검색에 O(logN)의 시간밖에 소요되지 않는다.
- 또한, 인덱스에서는 검색 대상 필드(들)의 값을 찾은 뒤, 그 값이 아닌 값을 처음으로 만나는 순간 더 이상 검색을 진행하지 않고 멈춘다(= Range Scan). 이것이 가능한 이유도 마찬가지로 인덱스가 검색 대상 필드(들)의 값을 기준으로 이미 정렬이 되어 있기 때문이다. 따라서 모든 레코드들을 일일이 뒤지면서(= Full Scan) 시간을 낭비할 필요가 없어진다.
이러한 특징으로 인해, 인덱스에서는 검색 대상 필드(들)의 값에 해당하는 레코드들의 주솟값을 상당히 빠른 속도로 찾아낼 수 있다. 그러면 이제 그렇게 찾아낸 레코드들의 주솟값들을 토대로 원래의 테이블에서 검색을 수행하기만 하면 된다.
그런데 여기서 하나 의문이 있다. 주솟값을 토대로 원래의 테이블에서 검색하는 것도 결국은 모든 레코드들을 일일이 뒤져야 하는 것(= Full Scan)은 아닐까? 결론부터 얘기하자면, 그렇지 않다. 데이터베이스의 테이블에서 각 레코드의 주솟값은 해당 레코드의 고유한 주소를 의미한다. 따라서 주솟값을 토대로 검색을 수행할 때는 훨씬 더 빠르게 원하는 레코드들을 찾아낼 수 있도록 내부적으로 구현이 되어 있다. 결국, 인덱스를 사용하는 이유는 찾고자 하는 레코드들의 주솟값들을 빠르게 유도해내기 위함이라고 할 수 있다.
참고로, 실제로 사용자는 인덱스를 한 번 생성해두고 나면 이후부터는 검색 등의 쿼리를 수행할 때 굳이 인덱스에 대한 명시를 다시 해줄 필요가 없다. 쿼리를 수행할 때 데이터베이스가 알아서 생성되어 있는 인덱스를 적절히 활용하여 동작할 것이기 때문이다. 또한, MySQL이나 PostgreSQL 등의 데이터베이스에서는 Primary Key로 지정되는 필드에 대해 자동으로 인덱스가 생성된다. 따라서 Primary Key로 지정된 필드의 값을 토대로 검색을 수행하는 경우 상당히 좋은 성능을 보이게 된다.
※ 인덱스 생성 SQL 문 예시 ('student' 테이블에서 'name' 필드를 대상으로 'index_name' 인덱스를 생성)
→ CREATE INDEX index_name ON student(name)
4. 인덱스 사용 시 주의할 점
인덱스를 사용하는 것의 장단점은 명확하다. 즉, 장점만 존재하는 것은 분명히 아니기 때문에 개발자는 상황에 따라 적절히 판단하여 인덱스를 사용할 줄 알아야 한다. 인덱스를 사용하기에 좋은 상황을 미리 한 줄로 요약하면 다음과 같다.
"삽입/수정/삭제의 빈도가 적고, 특정 필드를 대상으로 검색(조회)이 빈번한 테이블"
위 내용을 SQL 문의 용어로 다시 표현하자면 다음과 같다. 인덱스는 SELECT 문에서 사용되는 WHERE/JOIN 절에서 좋은 성능을 보이는 반면, INSERT/UPDATE/DELETE 등과 같이 테이블의 내용을 수정하는 동작에 대해서는 좋지 않은 성능을 보인다는 것이다. 각각에 대해 그 이유를 간단히 설명하자면 다음과 같다.
- INSERT : 새로운 레코드를 추가할 때, 테이블뿐만 아니라 인덱스에도 해당 레코드의 정보를 추가해줘야 한다. 그런데 인덱스에 레코드 하나를 추가하는 것이 결코 가벼운 동작은 아니다. 인덱스 내 모든 레코드들은 정렬이 되어 있어야 하기 때문에, 레코드를 새로 추가할 때도 (자료구조에 따라 구체적인 구현은 달라지겠지만) 적절한 자리를 찾아서 그곳에 삽입될 수 있도록 해야 한다.
- DELETE : 레코드를 삭제할 때, 원래의 테이블에서는 해당 레코드를 삭제하고 그 공간을 다른 레코드가 사용하게 한다. 그러나 인덱스에서는 해당 레코드에 삭제되었다는 표시만 남기므로 그 공간을 재활용할 수는 없다.
- UPDATE : 인덱스에서 (DELETE에서와 같이) 기존 레코드에 삭제되었다는 표시를 남기고 수정된 레코드의 정보를 추가해줘야 한다. 따라서 수정 작업이 빈번한 경우 인덱스의 크기가 지나치게 커질 수 있다.
이와 같이, 인덱스의 사용에도 분명한 단점들이 많이 존재한다. 그리고 굳이 언급하지는 않았지만, 인덱스를 사용하면 당연히 저장 공간도 더 많이 사용하게 된다. 따라서 인덱스의 사용 기준을 명확히 이해하고 때에 따라서 적절히 활용할 줄 아는 능력이 매우 중요하다. 물론 여기서 설명한 기준들 외에도, 어떤 컬럼들을 조합하여 인덱스를 생성해야 하는지, 어떠한 특성의 컬럼들에 대해서는 인덱스의 생성을 기피해야 하는지 등등 인덱스의 사용에 관한 다양한 기준들이 존재한다. 그러나 여기서는 개발 시에 꼭 숙지하고 있어야 하는 중요한 내용에 초점을 맞춰서 설명을 진행하였다는 점을 기억해주기 바란다.
5. B-Tree의 개념
B-Tree는 디스크 등의 보조 기억 장치에서 효율적으로 동작하도록 설계된 균형 잡힌 탐색 트리를 의미한다. 실제로, 데이터베이스나 파일 시스템 등에서 정보를 저장하기 위한 자료 구조로서 B-Tree 혹은 그것의 변종들(EX. B+Tree 등)을 많이 사용하게 된다. 탐색 트리라는 점에서는 이진 탐색 트리와 유사하고, 균형 잡힌 트리라는 측면에서는 레드 블랙 트리(Red Black Tree)와 유사하다. 하지만 B-Tree는 보조 기억 장치 대상의 입출력 연산을 최적화하는 것에 더욱 초점이 맞춰져 있다는 특징이 있다.
일반적으로 B-Tree는 디스크에 저장이 되며, 디스크에는 데이터들이 트랙 위에 일정 크기(EX. 2^11 byte ~ 2^14 byte)의 페이지 단위로 나열되어 있다. 그리고 B-Tree에 접근이 필요한 경우 해당 페이지를 메인 메모리로 읽어 들이게 되고(디스크 읽기), 그 페이지에서 수정이 발생하면 해당 내용을 다시 디스크에 써주게 된다(디스크 쓰기). 따라서 B-Tree의 실행 시간은 결국 디스크 읽기 및 쓰기 작업 시간에 상당히 의존적일 수밖에 없다. 그런데 플래터의 회전과 암의 움직임과 같이 기계적인 특성이 강한 디스크의 경우 접근 속도가 메인 메모리에 비해 월등히 느리다. 따라서 디스크에 한 번 접근할 때 최대한 많은 정보를 읽어 들이는 것이 중요하다는 결론이 도출된다.
이를 위해, B-Tree는 다음 그림과 같이 하나의 노드가 여러 개의 키와 여러 개의 자식 노드를 가질 수 있도록 한다. 이로 인해 일반적인 레드 블랙 트리에 비해서도 상당히 작은 높이(height)를 가지게 되어, 특정 키를 탐색할 때 디스크의 접근 횟수를 상당히 절감시킬 수 있다. 만약 B-Tree의 각 노드가 디스크의 한 페이지 정도의 크기로 설계된다면, 높이가 h인 B-Tree의 경우 탐색 시 디스크 접근을 최대 h번만 수행하면 된다. B-Tree의 높이도 이진 탐색 트리나 레드 블랙 트리와 마찬가지로 O(logN)으로 표현하긴 하지만, 하나의 노드가 여러 개의 키와 자식 노드를 가지기 때문에 log의 밑이 커져서 높이가 훨씬 작아지는 것이다.

※ 참고로 B-Tree의 변종인 B+Tree의 경우, 각 키와 연결된 데이터(Satellite Information) 혹은 그것을 가리키는 포인터가 오로지 리프 노드에만 존재하며, 다른 노드들은 오로지 키들과 자식 노드를 가리키는 포인터들만 저장한다. 반면에 B-Tree의 경우 모든 노드에 각 키와 연결된 데이터 혹은 그것을 가리키는 포인터가 저장된다. 한편, B+Tree는 리프 노드들이 연결 리스트 구조로 연결되어 있기 때문에, 인덱스로 사용될 경우 범위 검색에 더 큰 성능을 보인다. 이러한 이유로, 실제로 인덱스는 B-Tree보다 B+Tree로 더 많이 구현된다.
6. B-Tree의 탐색 과정 (참고)

7. B-Tree의 삽입/삭제 과정 (참고)
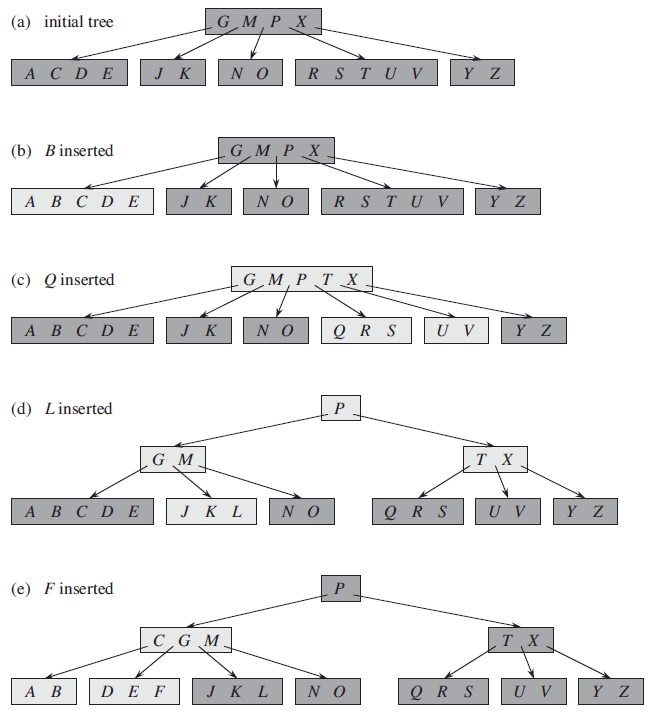
7-1. 삽입 과정
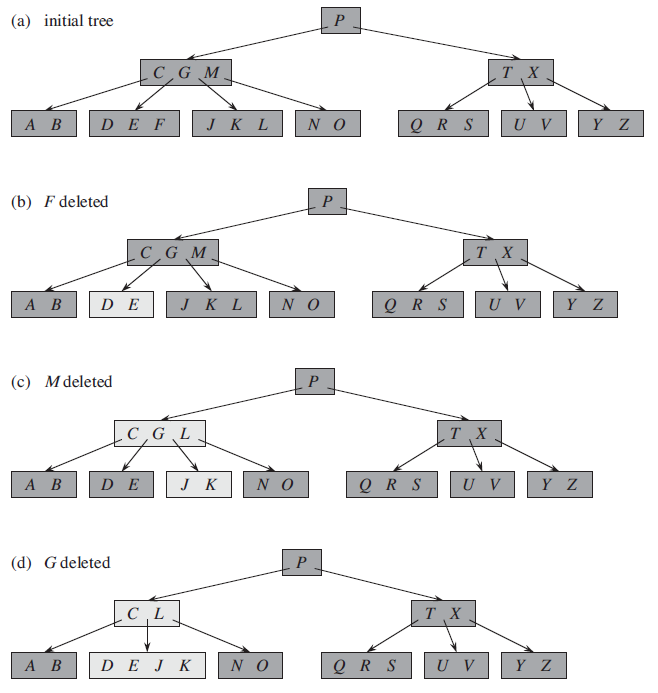
7-2. 삭제 과정
'데이터베이스 (Database)' 카테고리의 다른 글
| [Database] 트랜잭션 (Transaction) (0) | 2020.06.18 |
|---|---|
| [SQL] 서브쿼리 (Subquery) (0) | 2020.01.07 |