JavaScript와 달리 Python은 비동기 프로그래밍에 어색하다. 애초에 JavaScript는 비동기 방식으로 동작하도록 설계된 언어인 반면, Python은 동기 방식으로 동작하도록 설계된 언어이기 때문이다. 그래서 Python이 제공하는 대부분의 내장 API들은 동기 방식으로 동작한다. 하지만 Python 3.4 버전부터 asyncio 라이브러리가 표준으로 채택되고 Python 3.5 버전부터 async/await 키워드가 추가되면서, Python에서도 비동기 프로그래밍을 더욱더 쉽게 할 수 있게 되었다. 그렇다면 Python에서 asyncio 내장 라이브러리는 비동기 프로그래밍을 어떻게 실현한 것인지, 그 동작 원리를 한 번 알아보도록 하자. 단, asyncio 라이브러리의 기본적인 사용 방법은 알고 있다고 가정한다.
1. 코루틴과 제네레이터, async/await 키워드
코루틴(Coroutine)이란 특정 시점에 자신의 실행과 관련된 상태를 어딘가에 저장한 뒤 실행을 중단하고, 나중에 그 상태를 복원하여 실행을 재개할 수 있는 서브 루틴을 의미한다. 여기서 말하는 서브 루틴(Subroutine)이란 일반적으로 우리가 알고 있는 함수를 의미한다고 보면 된다. 즉, 코루틴은 함수 중에서도 조금 특별한 함수인 것이다. 그런데 여기서 하나 짚고 넘어가야 하는 건, 코루틴이나 서브 루틴은 Python에서만 쓰는 용어가 아닌 CS 전반에서 사용되는 용어라는 것이다. 따라서 우리는 'Python이 이러한 코루틴과 서브 루틴을 어떻게 구현하였는가'에 초점을 맞추는 것이 맞다.
Python에서 서브 루틴과 코루틴은 다음과 같이 정의된다. 우리가 이미 알고 있는 대로 def 키워드만을 이용하여 함수를 정의하면 서브 루틴이 되고, 앞에 async 키워드까지 붙여서 함수를 정의하면 코루틴이 된다.
# Subroutine (Synchronous Function)
def subroutine():
print('subroutine')
# Coroutine (Asynchronous Function)
async def coroutine():
print('coroutine')
그리고 async 키워드에서 알 수 있듯이 코루틴은 비동기 함수라고도 한다. 비동기(Asynchronous)라는 것은 쉽게 말해서 어떠한 작업이 완료되기를 기다리지 않고, 그 시간 동안 다른 작업을 하는 것을 말한다. 일반적인 Python 프로그램은 동기(Synchronous) 함수로만 이뤄져 있기 때문에, 항상 어떠한 작업이 완료되기를 기다린 후에 그다음 작업을 진행하게 된다. 하지만 Python에서도 코루틴을 이용하면 비동기 코드를 작성할 수 있기 때문에, 코루틴을 비동기 함수라고도 부르는 것이다. 아래 그림은 동기 방식의 실행 흐름과 비동기 방식의 실행 흐름을 비교한 것이다.
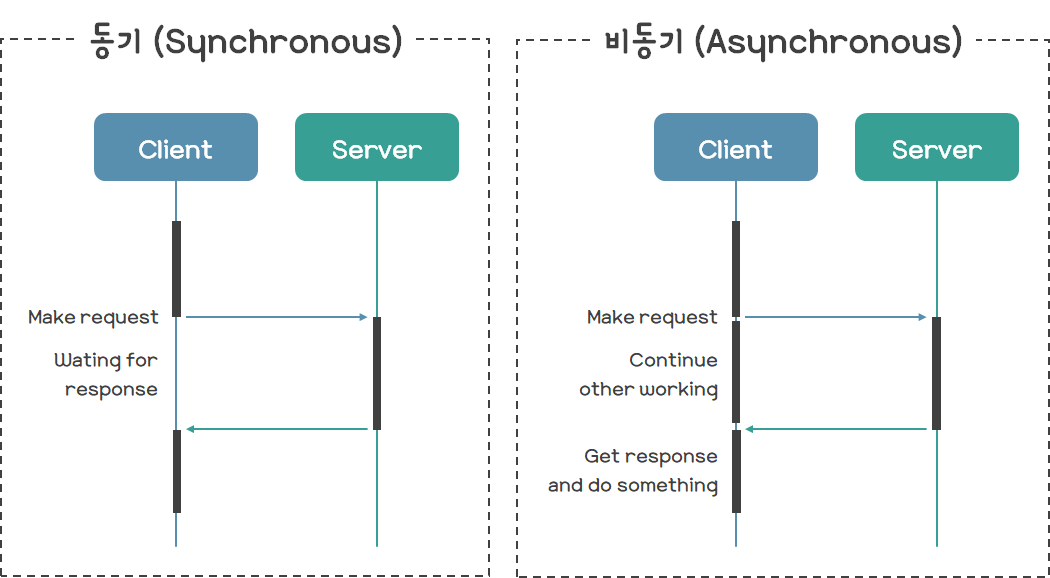
그런데 사실 Python에서 코루틴은 제네레이터를 기반으로 구현된다. 즉, Python에서 코루틴은 곧 제네레이터인 것이다. 왜 제네레이터로 구현한 것일까? 그것은 제네레이터가 yield 키워드를 breakpoint로 삼아 실행이 중단 및 재개될 수 있는 특징을 가지고 있기 때문이다. 실제로 Python 3.5 이전 버전에서는 코루틴을 직접 제네레이터 기반으로 작성해야 했다. async 키워드는 그러한 제네레이터를 조금 더 쉽게 작성할 수 있도록 돕는 문법적인 설탕에 불과하다.
📌 제네레이터의 실행 및 중단 (yield 키워드)
Caller는 제네레이터를 호출하여 제네레이터 객체(이하 gen)를 얻고, next(gen) 혹은 gen.send(값)을 호출함으로써 해당 제네레이터를 실행한다. 그렇게 실행된 제네레이터는 yield 키워드를 마주치는 순간 자신의 실행과 관련된 상태(스택, 실행 위치 등)를 저장한 뒤 실행을 중단하고, Caller에게 (yield 키워드의 뒤에 오는) 값을 넘겨준다. 그리고 이렇게 제어를 다시 넘겨받은 Caller가 다시 동일한 방법으로 해당 제네레이터를 실행하면, 해당 제네레이터는 아까 실행이 중단되었던 부분부터 다시 실행을 시작하게 된다. 이때 만약 Caller가 gen.send(값)을 호출함으로써 해당 제네레이터를 다시 실행한 것이었다면, 아까 실행이 중단되었던 부분에 위치한 yield 키워드 구문의 자리에는 send() 메소드의 인자에 해당하는 값이 채워진다. 결국, yield 키워드는 제네레이터가 Caller에게 값을 넘겨주는 것이라면 gen.send(값)은 Caller가 제네레이터에게 값을 넘겨주는 것이다. 참고로, yield 키워드를 모두 소진한 제네레이터를 실행하는 경우 StopIteration 예외가 발생하며, 이때 그 예외 객체의 value 필드에는 해당 제네레이터의 반환 값이 저장되어 있다.
따라서 제네레이터를 호출하면 제네레이터 객체(Generator Object)가 생성되어 반환되는 것처럼, 코루틴을 호출하면 제네레이터 객체와 유사한 코루틴 객체(Coroutine Object)라는 것이 생성되어 반환된다.
async def coroutine():
print('coroutine')
coroutine()
# 출력 : <coroutine object async_func at 0x015A9540>
# 주의 : 'coroutine'이 출력되지는 않음(코루틴이 실행되진 않음).
JavaScript에 익숙한 사람이라면 비동기 함수를 호출했을 때 반환되는 Promise 객체가 떠오를 것이다. 하지만 Python에서의 코루틴 객체는 Promise 객체와 조금 다르다. 가장 큰 차이점은, JavaScript에서는 비동기 함수를 호출하면 실제로 그 비동기 함수의 코드가 실행되면서 Promise 객체가 반환되지만, Python에서는 코루틴을 호출해도 코루틴 객체만 반환될 뿐 그 코루틴의 코드가 실행되지는 않는다는 것이다. 오히려, 뒤에서 설명할 태스크 객체(Task Object)가 Promise 객체와 매우 유사하다. 이에 대해서는 뒤에서 더 자세히 설명한다.
그러면 이제 await 키워드에 대해서도 알아보자. Python 3.5 이전 버전에서는 코루틴이 또 다른 코루틴을 실행하도록 하기 위해 yield from 키워드를 사용했었다. await 키워드도 async 키워드와 마찬가지로, 그러한 yield from 구문을 조금 더 쉽게 작성할 수 있도록 돕는 문법적인 설탕에 불과하다. 기존에는 yield from 키워드의 뒤에 제네레이터 객체를 두는 식이었다면, 이제는 await 키워드의 뒤에 코루틴 객체를 두면 된다. 이를 통해 코루틴이 또 다른 코루틴을 실행하도록 할 수 있다. 참고로, await 키워드의 뒤에는 코루틴 객체뿐 아니라 __await__() 메소드가 구현된 Awaitable 객체라면 무엇이든지 올 수 있다. 이러한 경우에는 __await__() 메소드를 호출하여 제네레이터 객체를 얻고 이를 통해 해당 제네레이터를 실행하는 방식으로 동작한다.
📌 제네레이터의 중첩 (yield from 키워드)
제네레이터가 다시 또 다른 제네레이터를 실행하는 것도 가능하다. yield from 키워드의 뒤에 또 다른 제네레이터에 해당하는 제네레이터 객체를 두면 된다. 이 구문이 의미하는 것은 현재 제네레이터의 실행을 중단하고 해당 제네레이터를 실행하라는 것이다. 그렇게 실행된 제네레이터가 어떠한 값을 yield 하면 Caller에 해당하는 제네레이터가 그 값을 받아서 그대로 yield 하는 효과를 보이며, 어떠한 값을 return 하면 Caller에 해당하는 제네레이터에서 실행이 중단되었던 부분에 위치한 yield from 키워드 구문의 자리에 그 값이 채워진다. 참고로, yield from 키워드의 뒤에는 제네레이터 객체뿐 아니라 __iter__() 메소드가 구현된 Iterable 객체라면 무엇이든지 올 수 있다. 이러한 경우에는 __iter__() 메소드를 호출하여 이터레이터 객체를 얻고 이를 통해 해당 이터레이터로부터 값을 하나씩 받는 방식으로 동작한다.
종합하면, 제네레이터와 코루틴의 대응 관계는 다음과 같이 나타낼 수 있다.
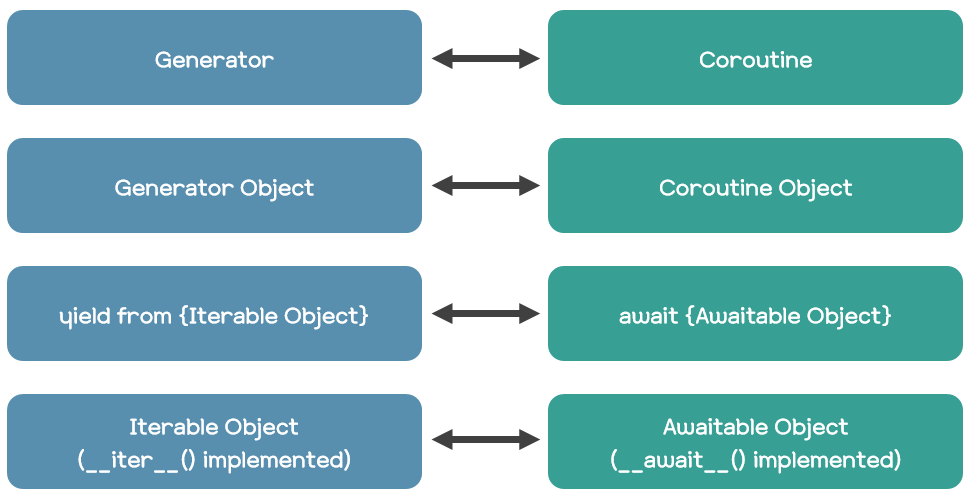
2. 퓨처 객체와 태스크 객체
이번에는 코루틴 객체와 비슷한 듯 다른, 퓨처 객체와 태스크 객체에 대해 알아보도록 하자. 이들은 코루틴 객체와 마찬가지로 await 키워드의 뒤에 올 수 있는 Awaitable 객체에 해당하며, asyncio 기반의 비동기 프로그래밍에서 아주 핵심적인 역할을 수행한다.
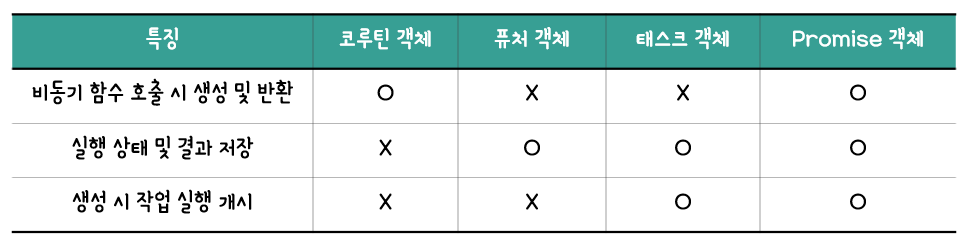
2-1. 퓨처 객체 (Future Object)
퓨처 객체는 어떠한 작업의 실행 상태 및 결과를 저장하는 객체이다. 여기서 말하는 실행 상태란 해당 작업이 진행 중인지, 취소되었는지, 종료되었는지를 말한다. 그래서 퓨처 객체는 PENDING, CANCELLED, FINISHED의 세 가지 상태 중 하나를 가진다. 이때 작업의 완료(Done)라 함은 CANCELLED 혹은 FINISHED 상태를 가리킨다. 그리고 실행 결과라 함은 해당 작업의 결과 값 혹은 그 작업을 진행하면서 발생한 예외 객체를 말한다. 예외가 발생한 경우에도 FINISHED 상태가 된다는 것에 주의하자.
퓨처 객체의 중요한 메소드 중 하나는 add_done_callback()이다. 이 메소드를 호출하면 해당 퓨처 객체가 완료(Done)될 때 호출될 함수를 등록할 수 있다. 이 메소드는 뒤에서 이벤트 루프의 동작 원리를 설명할 때 매우 중요하므로 기억해두자.
JavaScript에 익숙한 사람이라면 여기서도 Promise 객체가 떠오를 것이다. 똑같이 실행 상태 및 결과를 저장하기 때문이다. 그러나 퓨처 객체도 Promise 객체랑 유사하다고 보기는 힘들다. 단순히 어떠한 작업의 실행 상태 및 결과를 저장할 뿐, 그 작업의 실행을 개시하는 역할은 수행하지 않기 때문이다. 오히려, 바로 이어서 설명할 태스크 객체(Task Object)가 Promise 객체와 상당히 유사하다.
2-2. 태스크 객체 (Task Object)
태스크(Task)는 퓨처(Future)를 상속하는 클래스이다. 즉, 태스크 객체는 기본적으로 퓨처 객체의 기능을 전부 가지고 있기 때문에, 퓨처 객체와 마찬가지로 어떠한 작업의 실행 상태 및 결과를 저장한다. 그러나 퓨처 객체와 다른 점은, 태스크 객체는 그 어떠한 작업의 실행을 개시하는 역할도 수행한다는 것이다. 이를 위해 필요한 것이 바로 코루틴 객체이다. 실제로 태스크 객체는 생성될 때 코루틴 객체를 넘겨받아 _coro 필드에 저장한다. 결국, 태스크 객체는 코루틴 객체를 갖고 있는 특별한 종류의 퓨처 객체라고 볼 수 있다. 다만, 코루틴 객체와 달리 코루틴을 호출한다고 해서 생성 및 반환되는 것은 아니며, 태스크 객체를 생성하려면 asyncio.run() 함수 혹은 asyncio.create_task() 함수를 호출할 때 인자로 코루틴 객체를 넘겨줘야 한다.
태스크 객체는 생성되는 즉시 현재의 쓰레드에 설정되어 있는 이벤트 루프에게 자신의 __step() 메소드를 호출해줄 것을 요청한다. __step()은 자신의 코루틴 객체를 이용하여 해당 코루틴을 실행하는 메소드이다. 이것을 보고 '코루틴이 태스크로서 실행되도록 이벤트 루프에 예약을 건다'라고 표현한다. 뒤에서 알아보겠지만, asyncio.run() 함수 혹은 asyncio.create_task() 함수를 호출할 때 인자로 코루틴 객체를 넘겨주면 그 코루틴 객체로 태스크 객체가 생성되면서 해당 코루틴이 태스크로서 실행되도록 예약된다.
태스크 객체의 __step() 메소드가 호출되면 코루틴의 실행이 개시된다. 그렇게 처음 실행된 코루틴은 await 키워드를 이용하여 또 다른 코루틴을 부를 수 있고, 그 코루틴은 또다시 다른 코루틴을 부를 수도 있다. 이를 코루틴 체인(Coroutine Chain)이라고 부른다. 이처럼 하나의 태스크 객체는 현재의 태스크에 속하는 코루틴 체인의 실행을 관장하는 역할을 맡는다고 볼 수 있다.
이러한 연쇄 과정으로 코루틴을 호출하다 보면, 언젠가 Sleep 혹은 I/O 관련 코루틴(EX. asyncio.sleep() 등)을 await 하는 코드를 마주칠 수 있다. 태스크 객체는 이러한 상황을 감지하면 자신의 실행을 중단하고 이벤트 루프에게 제어를 넘긴다. 그러고 나면 이벤트 루프는 자신에게 실행을 예약해둔 태스크들 중 우선순위가 높은 것을 적절히 선택하여 이를 실행시키게 되고, 시간이 흘러 아까 실행이 중단되었던 태스크가 다시 실행할 수 있는 상태가 되면 이 태스크는 다시 이벤트 루프에게 실행을 예약해둔다. 그러면 언젠가 이벤트 루프에 의해 다시 선택을 받아 실행할 수 있게 될 것이다.
한편, 태스크 객체가 처음 실행한 코루틴의 실행이 완료되면, 즉 해당 코루틴이 모든 yield 키워드를 소진한 상태에서 return 함으로써 StopIteration 예외가 발생하면, 그 객체로부터 반환 값을 얻어서 자기 자신(태스크 객체)의 결과 값을 업데이트한다. 이는 해당 태스크의 실행이 완료된 상황을 의미하며, 따라서 이 태스크는 이제 더 이상 이벤트 루프에 의해 실행이 예약될 수 없게 된다. 참고로 asyncio.run() 함수가 실행되는 것은 이로 인해 실행된 태스크의 실행이 완료될 때까지를 의미하는 것이다.
※ 이벤트 루프의 실행 흐름 및 동작 원리에 대해서는 아래에서 다시 다룰 것이다. 그렇기 때문에 여기서 이해가 안 된 내용이 있어도 우선 넘어가고 아래의 내용까지 읽어보는 것을 권장한다.
3. 이벤트 루프의 실행 흐름 (동작 원리)
본격적으로, 이벤트 루프의 실행 흐름 및 동작 원리를 알아보자. Python에서 비동기 프로그래밍이 동작하는 원리 그 자체이다.
우선, 앞서 말했듯 코루틴을 호출하여 코루틴 객체가 생성 및 반환된다고 하여 해당 코루틴이 바로 실행되지 않는다는 것을 떠올리자. 그렇다면 코루틴을 실행시키는 코드는 무엇일까? Python에서 코루틴을 실행하는 방법은 대략 다음과 같이 세 가지이다.
await키워드asyncio.run()함수asyncio.create_task()함수
이 중에서 await 키워드는 코루틴 내에서만 사용할 수 있기 때문에, 맨 처음 코루틴을 실행하는 용도로는 사용할 수 없다. 최초에 한 번 코루틴이 실행되고 나면, 그 코루틴부터 시작해서 await 키워드를 이용하여 다른 코루틴을 호출할 수는 있다. 그렇다면 남은 건 2번과 3번이다. 이들은 코루틴 바깥에서 처음으로 코루틴을 실행할 수 있는, 즉 코루틴 체인으로 들어가는 일종의 엔트리 포인트이다.
그러나 일반적인 경우에 비동기 프로그래밍의 시작점은 2번이기 때문에, 여기서는 일단 2번에 대해 먼저 자세히 설명하겠다. 3번은 보통 태스크를 동시적으로 실행하고 싶은 경우에 사용하는 것이므로, 아래의 "태스크 동시 실행" 섹션에서 따로 설명하도록 하겠다.
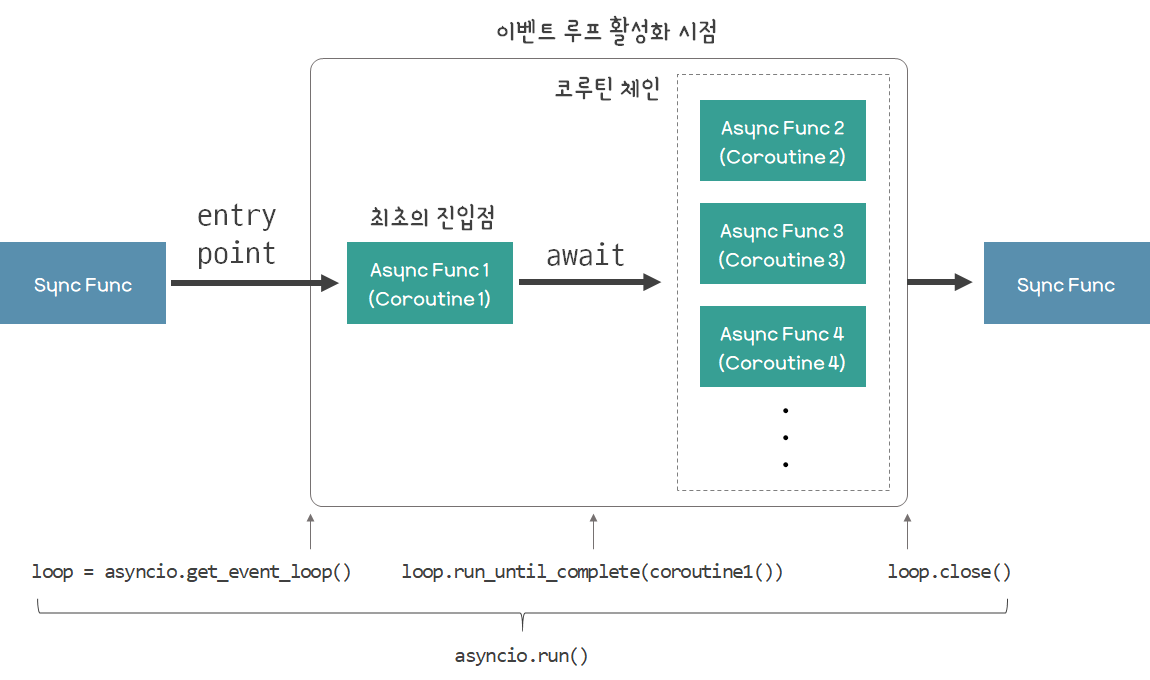
asyncio.run() 함수는 현재의 쓰레드에 새 이벤트 루프를 설정하고, 해당 이벤트 루프에서 인자로 넘어오는 코루틴 객체에 해당하는 코루틴을 태스크로 예약하여 실행시킨 뒤, 해당 태스크의 실행이 완료되면 이벤트 루프를 닫는 역할을 수행한다. 단, 이 함수는 3.7 버전 이상의 Python에서만 사용할 수 있기 때문에, 그 이전 버전에서는 다음과 같이 코드를 작성해야 한다. 여기서는 아래의 코드를 기준으로 동작 원리를 설명하도록 하겠다. 래핑 함수보다는 더 날것에 가깝기 때문이다.
loop = asyncio.get_event_loop()
loop.run_until_complete(first_coroutine())
loop.close()
아래는 위 코드의 의미를 다이어그램으로 나타낸 그림이다. 각 코드에 대한 설명은 아래에서 자세히 진행한다.
3-1. loop = asyncio.get_event_loop()
이는 현재 쓰레드에 설정된 이벤트 루프를 가져오는 함수이다. 그러나 만약 현재 쓰레드에 설정되어 있는 이벤트 루프가 없다면, 이벤트 루프를 새로 생성하여 이를 현재 쓰레드에 설정한 뒤 해당 이벤트 루프를 반환한다. 즉, 이 함수의 호출은 코루틴의 실행을 위해 이벤트 루프를 준비하는 과정으로 볼 수 있다.
그런데 이벤트 루프가 정확히 무엇일까? 추상적으로만 알고 있으면 개념이 잘 와닿지 않을 것이니, 구체적으로 쉽게 풀어보자면 다음과 같다. 이벤트 루프란, 무한 루프를 돌며 매 루프마다 작업(= 태스크)을 하나씩 실행시키는 로직을 의미한다. 따라서 위에서 언급했던, 현재 쓰레드에 이벤트 루프를 설정한다 함은 단순히 '이벤트 루프라는 로직을 실행시킬 수 있는 객체를 생성한 것' 정도로 이해하면 된다. 이벤트 루프 객체를 이용하여 실제로 이벤트 루프를 실행시키는 것은 아래에서 설명할 run_until_complete() 메소드를 호출하는 순간부터이다.
그리고 여기서 말하는 작업이라는 것은 곧 앞서 소개했던 태스크 객체에 대응하는 태스크(Task)이다. 태스크라는 것은 하나의 코루틴에서부터 출발하는 하나의 실행 흐름으로 볼 수 있다. 태스크의 실행과 관련한 자세한 내용은 아래에서 더 자세히 설명하겠다.
다음은 이벤트 루프가 실행되는 흐름을 아주 간단하게 표현한 코드이다. 이벤트 루프 객체를 이용하여 실제로 이벤트 루프를 실행시키면 대략 이러한 코드가 실행되는 것으로 상상하면 된다. (실제로는 훨씬 더 복잡할 것이다.)

3-2. loop.run_until_complete(first_coroutine())
앞서 생성한 이벤트 루프 객체를 이용하여 실제로 이벤트 루프를 실행시키는 함수이다.
① 태스크의 실행 (코루틴 체인의 형성)
인자로 넘어오는 코루틴 객체를 이용하여 태스크 객체를 생성하고, 그 과정에서 해당 태스크 객체가 나타내는 태스크의 실행이 이벤트 루프에 의해 즉시 예약된다. 처음에는 실행이 예약된 다른 태스크가 없기 때문에, 이벤트 루프는 이 태스크를 바로 실행할 것이다. 이때 태스크의 실행이란, 해당 태스크 객체의 __step() 메소드를 호출하는 것을 의미한다. 이 메소드는 코루틴 객체(_coro 필드에 저장되어 있음)의 send() 메소드를 호출함으로써 해당 코루틴을 실행하는 역할을 수행한다. 그러면 이 코루틴을 시작으로 await 키워드를 마주칠 때마다 연쇄적으로 코루틴을 호출하며 코루틴 체인을 형성하게 될 것이다.
② 코루틴 체인의 종착점 (await {Sleep 또는 I/O 관련 코루틴 객체})
await 키워드를 통해 코루틴 체인을 형성하며 코루틴을 실행하다 보면, 언젠가 Sleep 혹은 I/O 관련 코루틴(EX. asyncio.sleep() 등)을 await 하는 코드를 마주치게 될 것이다. 그런데 이러한 종류의 코루틴들은 퓨처 객체를 await 하도록 구현되어 있다.
※ 물론 안 마주칠 수도 있다. 코루틴 체인의 끝에서 이러한 await 코드 없이 단순히 return 해버릴 수도 있기 때문이다. 이러한 경우, 태스크 객체의 __step() 메소드에 StopIteration 예외를 발생시키면서 현재 태스크의 실행을 완료해버릴 것이다. 이와 관련한 설명은 아래에 있으니 일단 끝까지 읽어보자.
예를 들어 I/O 관련 코루틴이라고 해보자. 그러면 이 코루틴은 특정 소켓에 대해 데이터를 읽거나 쓰기 위해 해당 소켓의 상태를 검사한다. 만약 당장 읽거나 쓸 수 있는 데이터가 있다면, 단순히 yield 키워드만을 사용하여 태스크 객체의 __step() 메소드로까지 제어를 넘긴다. 그러면 태스크 객체는 바로 다시 자신의 실행을 이벤트 루프에게 예약하고 지금의 실행은 중단한 뒤 이벤트 루프에게 제어를 넘긴다. 이때 태스크의 실행을 예약한다 함은 곧 해당 태스크 객체의 __step() 메소드를 이벤트 루프의 콜백 큐에 등록하는 것을 의미한다는 것을 기억하자.
그러나 보통은 당장 읽거나 쓸 수 있는 데이터가 있지 않다. 따라서 보통의 경우에는 select() 함수를 이용하여 해당 소켓을 등록해두고, 해당 소켓에 바인딩된 퓨처 객체를 새로 생성하여 await 한다. 퓨처 객체의 __await__() 메소드는 자기 자신(퓨처 객체)을 yield 하도록 구현되어 있기 때문에, 이로 인해 해당 퓨처 객체는 코루틴 체인을 따라 태스크 객체의 __step() 메소드로까지 전달될 것이다. 우선 여기까지 설명을 하고, 이번에는 Sleep 관련 코루틴도 알아보자. 그 이후의 절차는 아래 섹션에서 설명한다.
※ select() 함수 : Unix의 select() 함수를 래핑 한 Python 함수로, 특정 소켓들에 대해 데이터를 읽거나 쓸 준비가 될 때까지 (원하는 시간만큼) 기다릴 수 있게 하는 Blocking 함수이다. 이는 (원하는 시간만큼) 기다린 후 데이터를 읽거나 쓸 준비가 된 소켓들을 반환한다.
Sleep 관련 코루틴의 경우, 이벤트 루프 자체의 타이머를 이용한다. 만약 asyncio.sleep(1)이라면, 이 코루틴은 퓨처 객체를 하나 생성한 뒤 이벤트 루프에게는 1초 뒤에 해당 퓨처 객체의 결과 값을 업데이트하도록 요청한다. 그리고 그 퓨처 객체를 await 한다. 그러면 마찬가지로 해당 퓨처 객체가 코루틴 체인을 따라 태스크 객체의 __step() 메소드로까지 전달될 것이다. 그렇다면 이제 그렇게 전달된 퓨처 객체를 태스크 객체가 어떻게 처리하는지 알아보자.
③ 태스크 객체의 퓨처 객체 처리
태스크 객체는 yield 된 퓨처 객체를 받으면 우선 이것을 자신의 _fut_waiter 필드에 저장한다(바인딩한다). 그리고 퓨처 객체의 add_done_callback() 메소드를 호출하여, 해당 퓨처 객체가 완료 상태가 될 때 이벤트 루프에게 실행을 예약할 콜백 함수를 등록한다. 이때 등록하는 함수는 곧 자기 자신의 __step() 메소드라고 생각해도 된다. 이러한 콜백 함수의 실행을 이벤트 루프에게 예약한다는 것은 곧 해당 태스크의 실행을 예약한다는 것과 같은 말이다.
그러고 나면 이제 태스크 객체는 자신의 실행을 중단하고 제어를 이벤트 루프에게 넘긴다. 그러면 지금과 같이 퓨처 객체에 바인딩되어 있는 태스크 객체는 더 이상 이벤트 루프에 의해 실행되지 못할 것이다. _fut_waiter 필드의 이름이 나타내듯이, 어떠한 퓨처 객체를 기다리고 있을 때는 실행되면 안 되기 때문이다. 아무튼 그렇게 제어가 넘어가고 나면, 이벤트 루프는 다시 자신에게 실행을 예약해둔 태스크(정확히는 콜백 함수)들 중 우선순위가 높은 것을 적절히 선택하여 이를 실행시킨다. 이벤트 루프는 이러한 과정을 반복하며 여러 태스크들을 동시적으로(Concurrent, not Parallel) 실행하는 역할을 맡는다.
④ 이벤트 루프의 Polling (I/O 소켓 검사)
그런데 만약 더 이상 자신에게 실행을 예약해둔 태스크가 없게 되면, 이벤트 루프는 그 시간을 낭비하지 않고 select() 함수를 이용하여 데이터를 읽거나 쓸 준비가 된 소켓을 계속 찾는다. 만약 데이터를 읽거나 쓸 준비가 된 소켓을 찾게 되면, 그 소켓에 바인딩되어 있는 퓨처 객체의 결과 값을 업데이트해주고, 이로 인해 이 순간 아까 등록해두었던 콜백 함수의 실행이 이벤트 루프에서 예약될 것이다. 다시 강조하지만, 콜백 함수의 실행을 예약한다는 건 곧 해당 태스크의 실행을 예약한다는 말이다.
⑤ 태스크 객체의 실행 재개 (__step() 메소드 재실행)
그러면 이벤트 루프가 실행이 예약된 태스크를 실제로 실행시키는 과정을 한 번 살펴보자. 태스크의 실행이란 곧 해당 태스크 객체의 __step() 메소드가 호출되는 것을 의미한다. 이 메소드는 먼저 자기 자신(태스크 객체)과 퓨처 객체의 바인딩을 해제함으로써 더 이상 기다리는 퓨처 객체가 없음을 나타내도록 하고, 다시 자신의 코루틴 객체에 대해 send() 메소드를 호출함으로써 해당 코루틴의 실행을 재개하게 된다. 그러면 다시 해당 퓨처 객체의 __await()__ 메소드에서 실행이 중단되었던 부분(자기 자신을 yield 하는 부분)까지 가게 된다.
__await()__ 메소드로까지 돌아왔을 때, 만약 I/O 관련 코루틴 때문에 기다리고 있었던 거라면 이제는 해당 소켓에 대해 데이터를 읽거나 쓸 준비가 되었다는 것이므로 해당 소켓(자기 자신에 바인딩되어 있음)에 대해 데이터를 읽거나 쓴 다음 그 값을 return 할 것이다. 반면에 Sleep 관련 코루틴 때문이었다면 바로 return 할 것이다.
⑥ 최초 코루틴의 Return (태스크 실행의 종료)
이러한 과정을 반복하다 보면 언젠가 태스크가 실행한 최초의 코루틴이 return 해야 하는 시점에 도달할 것이고, 이로 인해 해당 태스크 객체의 __step() 메소드에선 StopIteration 예외가 발생할 것이다. 그러면 태스크 객체는 그 예외 객체의 value 필드 값으로 자기 자신의 결과 값을 업데이트하고, 자신의 실행을 종료한다. 그러면 이 태스크는 더 이상 이벤트 루프에 의해 실행이 예약되지 않고 버려진다. loop.run_until_complete() 함수의 실행이 끝나는 시점이 이때이다. 자신이 실행한 태스크가 종료되었기 때문이다. 그리고 그 태스크 객체의 결과 값이 곧 loop.run_until_complete() 함수의 반환 값이다.
3-3. loop.close()
loop.run_until_complete() 함수의 실행이 끝났다는 것은 이제 해당 이벤트 루프가 실행되지 않는다는 것이다. 따라서 이벤트 루프를 닫아줘야 하는데, 이 역할을 수행하는 것이 loop.close() 함수이다. 이는 이벤트 루프에 남아 있는 모든 데이터(EX. 아직 실행이 종료되지 않은 태스크)들을 제거한다. 그래서 만약 loop.run_until_complete() 함수의 실행이 끝나고 loop.close()에 의해 이벤트 루프까지 닫히는 시점에 여전히 실행이 완료되지 않은 태스크가 남아 있다면, "Task was destroyed but it is pending!"라는 워닝 메시지가 출력될 것이다.
다음은 지금까지 설명한 이벤트 루프의 실행 흐름 및 동작 원리를 나타낸 다이어그램이다.
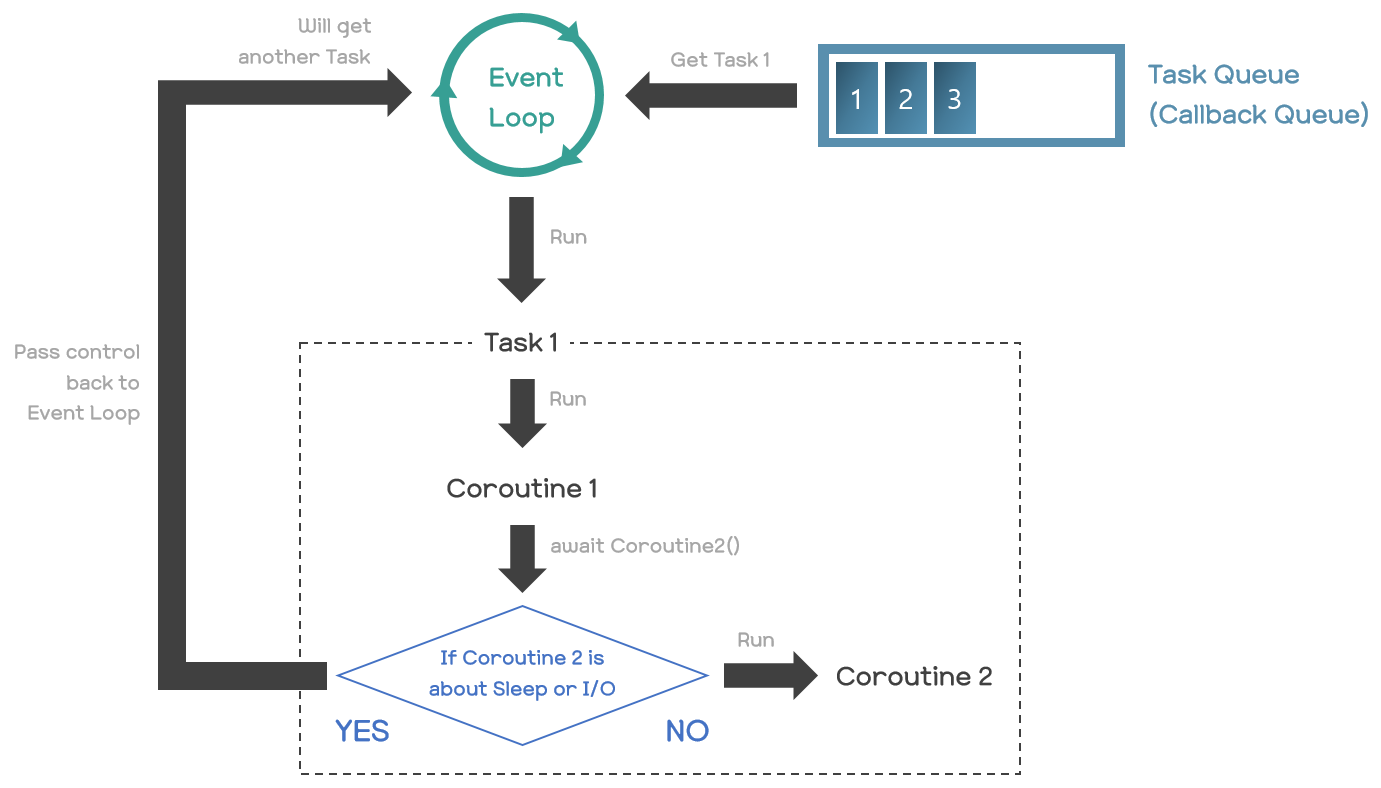
4. 태스크 동시 실행 : asyncio.create_task() 함수
위에서 이벤트 루프가 태스크들을 동시적으로(Concurrent, not Parallel) 실행한다고 설명하였다. 그런데 사실 asyncio.run() 함수는 기본적으로 하나의 태스크만을 생성하여 실행한다. 따라서 코루틴 체인 과정에서 추가적인 태스크를 생성하여 실행하지 않았다면 현재의 태스크가 중단되었을 때 이벤트 루프는 실행시킬 다른 태스크가 없게 된다. 태스크가 한 개라면 동시적인(Concurrent) 실행을 하는 것이 애초에 말이 되지 않는 것이다.
※ 여기서 말하는 동시 실행이란 Parallel이 아닌 Concurrent를 말한다. 즉, 엄밀한 의미의 동시가 아니라 여러 태스크들을 왔다 갔다 하며 한 쓰레드에서 실행하는 개념인 것이다. 따라서 총 실행 시간은 같거나 오히려 더 늘어난다(문맥 전환 비용 때문).
따라서 동시적인(Concurrent) 실행을 위해서는 asyncio.create_task() 함수를 호출함으로써 태스크를 추가로 생성하여 실행해야 한다. 이 함수를 호출할 때 코루틴 객체를 인자로 넘기면, 해당 코루틴 객체를 이용하여 태스크 객체를 생성하고 이를 반환한다. 그리고 앞서 말했듯 태스크 객체가 생성되면 해당 태스크 객체가 나타내는 태스크의 실행이 이벤트 루프에 의해 즉시 예약된다(즉시 실행이 아니다). 단, 이 함수는 3.7 버전 이상의 Python에서만 사용할 수 있기 때문에, 그 이전 버전에서는 asyncio.ensure_future() 함수를 대신 사용해야 한다.
다음으로, 모든 퓨처 객체(태스크 객체 포함)들이 완료 상태가 될 때까지 기다리는 함수가 asyncio.gather()이다. 이 함수는 인자로 여러 개의 Awaitable 객체들을 받을 수 있는데, 만약 코루틴 객체를 받으면 이는 자동으로 태스크 객체로 래핑이 된다. 따라서 사실상 퓨처 객체(태스크 객체 포함)만 넘어간다고 생각해도 된다. 그리고 모든 퓨처 객체들이 완료 상태가 되면 그것들의 결과 값들을 리스트 형태로 반환한다. 그 순서는 인자로 넘긴 순서와 동일하다. 이 함수는 await 키워드의 뒤에서 호출될 수 있는 코루틴의 일종이다.
예시 코드를 통해 한 번 알아보자.
import asyncio
import time
async def sleep(sec):
await asyncio.sleep(sec)
return sec
async def main():
sec_list = [1, 2]
tasks = [asyncio.create_task(sleep(sec)) for sec in sec_list] # [Task 1 객체, Task 2 객체]
tasks_results = await asyncio.gather(*tasks) # [Task 1 객체의 결과 값, Task 2 객체의 결과 값]
return tasks_results
start = time.time()
loop = asyncio.get_event_loop()
result = loop.run_until_complete(main())
loop.close()
end = time.time()
print('result : {}'.format(result))
print('total time : {0:.2f} sec'.format(end - start))
# 출력 결과
# result : [1, 2]
# total time : 2.00 sec
위 예시 코드의 실행 흐름을 파악해보면 다음과 같다.
- loop.run_until_complete() 함수에 의해 Task 0가 실행되고, 이로 인해 main() 코루틴이 실행된다.
- main() 코루틴은 asyncio.create_task() 함수를 통해 Task 1, Task 2 객체를 생성하고 실행을 예약한다.
- asyncio.gather() 코루틴은 Task 1 객체를 await 한다.
- Task 0는 Task 1 객체가 완료 상태가 될 때까지 기다리도록 하고, 이벤트 루프에게 제어를 넘긴다.
- 이벤트 루프가 Task 1을 실행한다.
- Task 1은 sleep(1) 코루틴을 실행하고, 다시 asyncio.sleep(1) 코루틴을 실행한다.
- asyncio.sleep(1) 코루틴은 Future 1 객체를 만들고, 1초 뒤에 Future 1 객체의 결과 값이 갱신되도록 이벤트 루프에 예약을 건 뒤, Future 1 객체를 await 한다.
- Task 1은 Future 1 객체가 완료 상태가 될 때까지 기다리도록 하고, 이벤트 루프에게 제어를 넘긴다.
- 이벤트 루프가 Task 2를 실행한다.
- Task 2는 sleep(2) 코루틴을 실행하고, 다시 asyncio.sleep(2) 코루틴을 실행한다.
- asyncio.sleep(2) 코루틴은 Future 2 객체를 만들고, 2초 뒤에 Future 2 객체의 결과 값이 갱신되도록 이벤트 루프에 예약을 건 뒤, Future 2 객체를 await 한다.
- Task 2는 Future 2 객체가 완료 상태가 될 때까지 기다리도록 하고, 이벤트 루프에게 제어를 넘긴다.
- 이제 이벤트 루프는 실행할 태스크가 없으므로 아무것도 하지 않는다.
- 그러다가 1초가 지나면 이벤트 루프는 Future 1 객체의 결과 값을 갱신한다. 이로 인해 Future 1 객체가 완료 상태가 될 때까지 기다리던 Task 1의 실행이 다시 예약된다.
- 이벤트 루프가 Task 1을 실행한다.
- asyncio.sleep(1) 코루틴으로 돌아가서 실행이 중단되었던 부분부터 실행을 재개한다.
- asyncio.sleep(1) 코루틴이 리턴하고, sleep(1) 코루틴도 리턴한다. 이때 반환 값은 1이다.
- Task 1 객체의 결과 값이 1로 설정되면서 Task 1의 실행이 완료된다. 이로 인해 Task 1 객체가 완료 상태가 될 때까지 기다리던 Task 0의 실행이 다시 예약된다.
- 이벤트 루프가 Task 0를 실행한다.
- asyncio.gather() 코루틴으로 돌아가서 실행이 중단되었던 부분부터 실행을 재개한다.
- asyncio.gather() 코루틴은 Task 1 객체의 결과 값을 저장하고, Task 2 객체를 await 한다.
- Task 0는 Task 2 객체가 완료 상태가 될 때까지 기다리도록 하고, 이벤트 루프에게 제어를 넘긴다.
- 이제 이벤트 루프는 실행할 태스크가 없으므로 아무것도 하지 않는다.
- 그러다가 1초가 더 지나면 이벤트 루프는 Future 2 객체의 결과 값을 갱신한다. 이로 인해 Future 2 객체가 완료 상태가 될 때까지 기다리던 Task 2의 실행이 다시 예약된다.
- 이벤트 루프가 Task 2를 실행한다.
- asyncio.sleep(2) 코루틴으로 돌아가서 실행이 중단되었던 부분부터 실행을 재개한다.
- asyncio.sleep(2) 코루틴이 리턴하고, sleep(2) 코루틴도 리턴한다. 이때 반환 값은 2이다.
- Task 2 객체의 결과 값이 2로 설정되면서 Task 2의 실행이 완료된다. 이로 인해 Task 2 객체가 완료 상태가 될 때까지 기다리던 Task 0의 실행이 다시 예약된다.
- 이벤트 루프가 Task 0를 실행한다.
- asyncio.gather() 코루틴으로 돌아가서 실행이 중단되었던 부분부터 실행을 재개한다.
- asyncio.gather() 코루틴은 [Task1 객체의 결과 값, Task 2 객체의 결과 값], 즉 [1, 2]를 리턴한다.
- main() 코루틴도 리턴한다. 이때 반환 값은 [1, 2]이다.
- Task 0 객체의 결과 값이 [1, 2]로 설정되면서 Task 0의 실행이 완료된다.
- loop.run_until_complete()의 실행이 완료되고, 이벤트 루프를 닫는다.
5. 동기 함수를 코루틴처럼 쓰기 : loop.run_in_executor() 메소드
우리가 지금까지 알아본 원리에 따르면, 결국 비동기 프로그래밍의 효과를 보기 위해서는 현재의 쓰레드 실행과 무관하게 다른 곳에서 어떠한 작업을 할 수 있어야 한다. 그 대표적인 예시가 Sleep 혹은 I/O 관련 코루틴이었다. Sleep의 경우에는 이벤트 루프가 자체적으로 타이머를 가지고 있기 때문에, 그리고 I/O 관련 코루틴은 CPU가 열심히 일하는 동안 I/O 장치가 일해주면 되기 때문에 현재의 실행 흐름을 Block 하지 않고 다른 작업을 먼저 할 수 있었던 것이다.
그런데 사실 Python이 가지고 있는 대부분의 API는 동기 방식으로 동작한다. 애초에 동기 방식으로 동작하도록 설계된 언어이기 때문이다. 예를 들어, asyncio.sleep() 함수가 제공되기 전에는 time.sleep() 함수를 사용했는데, 이는 현재의 실행 흐름을 Block 하는 함수였다. 그리고 requests 라이브러리가 제공하는 requests.get(), requests.post() 등의 함수도 현재의 실행 흐름을 Block 하는 함수이다. 이러한 함수들을 이용해서는 비동기 프로그래밍이 불가능할 듯하다. 비동기 프로그래밍이 가능하려면 그러한 작업을 다른 어딘가에 맡겨 놓고 퓨처 객체를 await 하면서 현재 실행 중인 태스크의 제어를 이벤트 루프에게 넘겨야 하기 때문이다.
이때 사용하는 것이 바로 loop.run_in_executor() 메소드이다. loop는 이벤트 루프 객체이다. 어렵게 설명하면 한도 끝도 없겠지만, 간단하게 얘기해서 이 메소드는 동기 함수를 별도의 쓰레드에서 실행시킴으로써 마치 Sleep 혹은 I/O 관련 코루틴처럼 사용할 수 있게 해주는 것이다. 비동기 프로그래밍을 하려면 어떤 작업을 '다른 어딘가(= 별도의 쓰레드)'에 맡겨야 하기 때문이다.
이 함수의 사용 방법을 바로 한 번 알아보자. 이 함수의 반환 값은 퓨처 객체이기 때문에, await 키워드의 뒤에 올 수 있다.
import asyncio
import time
async def sleep(sec):
await loop.run_in_executor(None, time.sleep, sec) # time.sleep(sec)
return sec
async def main():
sec_list = [1, 2]
tasks = [asyncio.create_task(sleep(sec)) for sec in sec_list] # [Task 1 객체, Task 2 객체]
tasks_results = await asyncio.gather(*tasks) # [Task 1 객체의 결과 값, Task 2 객체의 결과 값]
return tasks_results
start = time.time()
loop = asyncio.get_event_loop()
result = loop.run_until_complete(main())
loop.close()
end = time.time()
print('result : {}'.format(result))
print('total time : {0:.2f} sec'.format(end - start))
# 출력 결과
# result : [1, 2]
# total time : 2.03 sec
원래는 Blocking 함수인 time.sleep() 함수가 마치 asyncio.sleep() 함수처럼 동작할 수 있도록 하였다. loop.run_in_executor() 메소드의 첫 번째 인자로 넘어가는 None은 실행기를 명시적으로 지정하지 않고 기본 실행기를 사용하겠다는 것인데, 직접 실행기를 지정하면 워커 쓰레드를 원하는 개수만큼 생성하는 것이 가능하다. 두 번째 인자에는 함수 이름을 넘기고, 세 번째 인자부터는 그 함수를 호출할 때 넘길 인자들을 하나씩 넘기면 된다.
발췌 : A ThreadPoolExecutor starts its worker threads and then calls each of the provided functions once in a thread. This example shows how a coroutine yield control to the event loop while blocking functions run in separate threads, and then wake back up when those functions are finished. (출처)
※ 만약 단일 코어 CPU라면 멀티 쓰레딩을 하더라도 병렬(Parallel) 실행이 불가하다. 병렬 실행을 하려면 멀티 코어여야 한다.
'파이썬 (Python)' 카테고리의 다른 글
| [Python] GIL (Global Interpreter Lock) 이해하기 (9) | 2021.07.03 |
|---|---|
| [Python] 정규 표현식(정규식) 사용하기 (2) | 2021.03.04 |
| [Python] bytes, bytearray, 인코딩 및 디코딩 (0) | 2020.07.09 |
| [Python] Iterator, Generator (0) | 2020.01.11 |
| [Python] 객체와 기본 자료형 (0) | 2020.01.11 |