이번 포스팅은 Python만의 특징 중 하나인 GIL(Global Interpreter Lock)의 개념에 대해 알아볼 것이다. Python 프로그래머라면 한 번쯤은 들어봤을 법한 용어지만, 정확하게 알고 있지 못한 분들도 많을 것이다. 이 기회에 제대로 한 번 정리해보자.
1. Python 인터프리터란?
GIL을 이해하려면 먼저 Python 인터프리터란 것이 정확히 무엇인지 알아야 한다. Python 인터프리터란, Python으로 작성된 코드를 한 줄씩 읽으면서 실행하는 프로그램을 말한다. 그 프로그램의 구현체로는 여러 가지가 있을 수 있는데, 현재 Python 인터프리터의 표준 구현체로 받아들여지고 있는 것은 바로 CPython이다. CPython은 C 언어를 이용하여 구현한 Python 인터프리터이다. 이번 포스팅에서 다루는 내용은 전부 CPython을 기준으로 함을 미리 밝힌다.
2. GIL (Global Interpreter Lock)
그러면 본격적으로 GIL의 개념에 대해 알아보자. GIL은 Global Interpreter Lock(전역 인터프리터 락)의 약자이다. 먼저, Python 위키에서 말하고 있는 GIL의 정의는 다음과 같다.
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. This lock is necessary mainly because CPython's memory management is not thread-safe.
해석하자면, Python의 객체들에 대한 접근을 보호하는 일종의 뮤텍스(Mutex)로서, 여러 개의 쓰레드가 파이썬 코드를 동시에 실행하지 못하도록 하는 것이라고 한다. 즉, 한 프로세스 내에서, Python 인터프리터는 한 시점에 하나의 쓰레드에 의해서만 실행될 수 있다는 것이다. 멀티 쓰레딩이 불가능하다는 것이 아니다. 원래 멀티 코어라면 멀티 쓰레딩 시에 여러 개의 쓰레드가 여러 코어에서 병렬(Parallel) 실행될 수 있는데, Python에서는 그러한 병렬 실행이 불가능하다는 것뿐이다. 이를 그림으로 나타내면 다음과 같다.
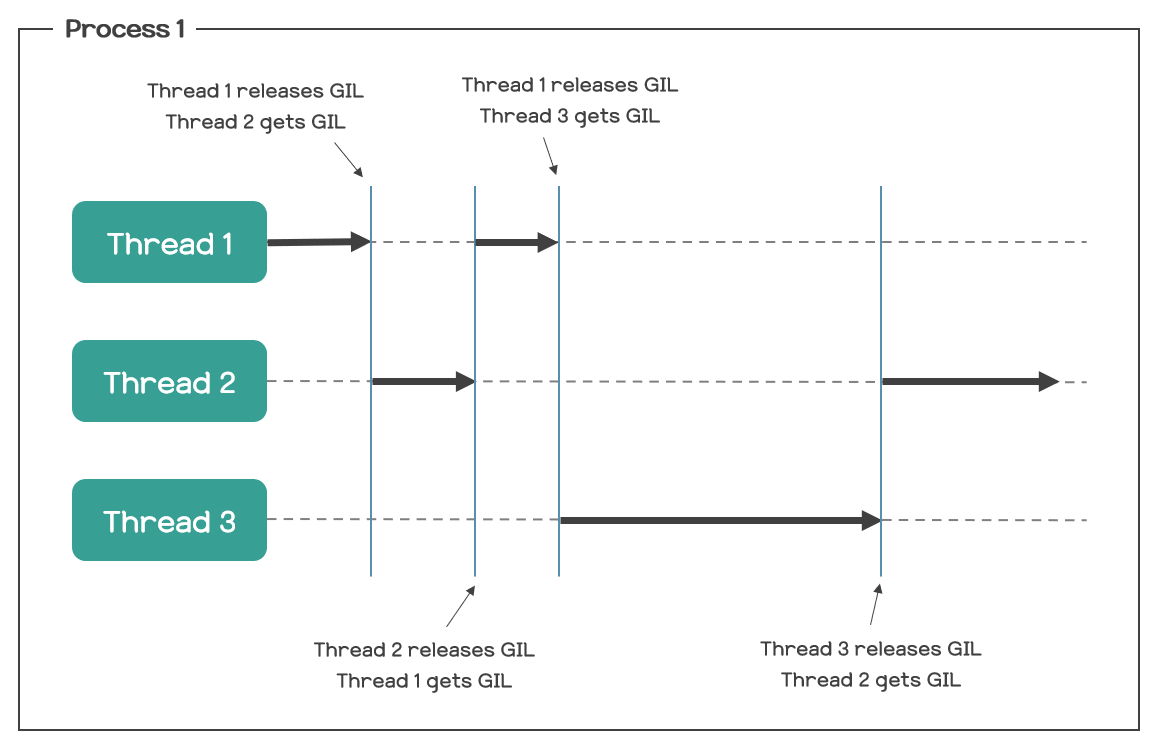
3. GIL이 왜 필요한가?
괜히 멀티 쓰레딩 시 병렬 실행만 불가능해지고, GIL이 왜 필요한가 싶을 수 있다. 사실, 앞서 소개한 Python 위키에서의 GIL 정의가 이 의문에 대해 답을 해준다. 그것은 바로, GIL이 Python의 객체들에 대한 접근을 보호하는 일종의 뮤텍스(Mutex)라는 것이다. 이것이 무슨 말인지 한 번 차근차근 자세히 알아보자.
먼저, Python에서 모든 것은 객체(Object)이다. 그리고 각 객체는 참조 횟수(Reference Count)를 저장하기 위한 필드를 갖고 있다. 참조 횟수란 그 객체를 가리키는 참조가 몇 개 존재하는지를 나타내는 것으로, Python에서의 GC(Garbage Collection)는 이러한 참조 횟수가 0이 되면 해당 객체를 메모리에서 삭제시키는 메커니즘으로 동작하고 있다. 참고로, sys 라이브러리의 getrefcount() 함수를 사용하면 특정 객체의 참조 횟수를 알아낼 수 있다.
import sys
# x의 참조 횟수 : 1
x = []
# x의 참조 횟수 : 2
y = x
# getrefcount() 함수의 매개변수 할당 시 x의 참조 횟수가 1 증가(3이 됨)
# getrefcount() 함수의 반환 시 x의 참조 횟수가 다시 1 감소(2가 됨)
sys.getrefcount(x)
# 출력 결과 : 3
그렇다면 이것이 GIL이랑 무슨 상관인 걸까? 참조 횟수에 기반하여 GC를 진행하는 Python의 특성상, 여러 개의 쓰레드가 Python 인터프리터를 동시에 실행하면 Race Condition이 발생할 수 있기 때문이다. Race Condition이란, 하나의 값에 여러 쓰레드가 동시에 접근함으로써 값이 올바르지 않게 읽히거나 쓰일 수 있는 상태를 말한다. 이러한 상황을 보고 Thread-safe 하지 않다고 표현하기도 한다.
즉, 여러 쓰레드가 Python 인터프리터를 동시에 실행할 수 있게 두면 각 객체의 참조 횟수가 올바르게 관리되지 못할 수도 있고, 이로 인해 GC가 제대로 동작하지 않을 수도 있다는 말이다. 물론 이러한 Race Condition은 뮤텍스(Mutex)를 이용하면 예방할 수 있다.
뮤텍스(Mutex)란, 멀티 쓰레딩 환경에서 여러 개의 쓰레드가 어떠한 공유 자원에 접근 가능할 때 그 공유 자원에 접근하기 위해 가지고 있어야 하는 일종의 열쇠와 같은 것이다. 만약 한 쓰레드가 어떠한 공유 자원에 대한 뮤텍스를 가지고 있다면, 다른 쓰레드들은 그 공유 자원에 접근하고 싶을 때도 그 공유 자원에 접근하고 있는 쓰레드가 뮤텍스를 풀어줄 때까지는 기다려야 한다. 다음 그림은 뮤텍스의 개념을 비유적으로 표현한 그림이다.
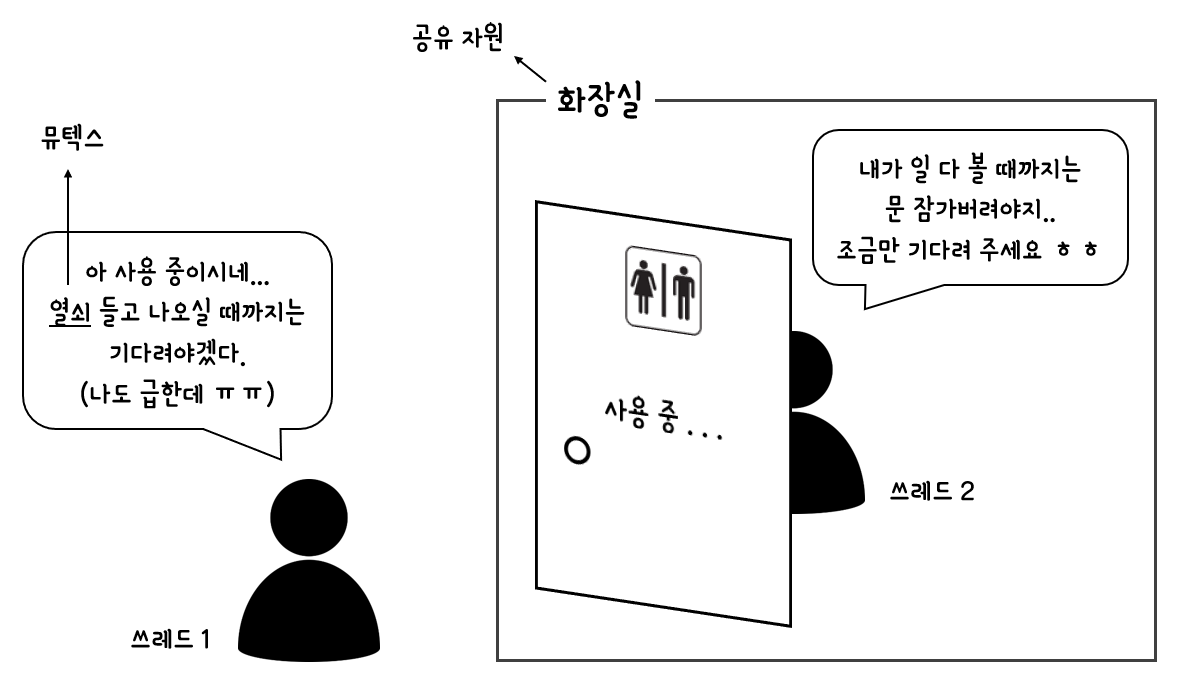
그런데 앞서 말했듯이, Python에서 모든 것은 객체이고, 객체는 모두 참조 횟수를 가진다. 따라서 GC의 올바른 동작을 보장하려면 결국 모든 객체에 대해 뮤텍스를 걸어줘야 한다는 말이 된다. 이는 굉장히 비효율적이며, 만약 이를 프로그래머에게 맡길 경우 상당히 많은 실수를 유발할 수도 있는 문제이다.
그래서 결국 Python은 마음 편한 전략을 택하였다. 애초에 한 쓰레드가 Python 인터프리터를 실행하고 있을 때는 다른 쓰레드들이 Python 인터프리터를 실행하지 못하도록 막는 것이다. 이를 보고 "인터프리터를 잠갔다"라고 표현한다. 즉, Python 코드를 한 줄씩 읽어서 실행하는 행위가 동시에 일어날 수 없게 하는 것이다. 그러면 모든 객체의 참조 횟수에 대한 Race Condition을 고민할 필요도 없어진다. 뮤텍스를 일일이 걸어줄 필요도 없어지는 것이다. 이것의 GIL의 존재 이유이다.
4. 그렇다면 Python에서 멀티 쓰레딩은 무조건 나쁜가?
위에서 설명한 것만 보면, Python에서는 GIL 때문에 멀티 쓰레딩을 쓰지 않는 게 좋아 보인다. 실제로, CPU 연산의 비중이 큰 작업을 할 때 멀티 쓰레딩은 오히려 성능을 떨어뜨린다. 병렬적인 실행은 불가능한데 괜히 문맥 전환(Context Switching) 비용만 잡아먹기 때문이다. 다음 예시 코드를 보자. 멀티 쓰레딩을 사용하니 오히려 더 느려진 걸 볼 수 있다.
import time
import threading
def loop():
for i in range(50000000):
pass
# Single Thread
start = time.time()
loop()
loop()
end = time.time()
print('[Single Thread] total time : {}'.format(end - start))
# Multi Thread
start = time.time()
thread1 = threading.Thread(target=loop)
thread2 = threading.Thread(target=loop)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
print('[Multi Thread] total time : {}'.format(end - start))
# [Single Thread] total time : 2.3374178409576416
# [Multi Thread] total time : 3.4128201007843018
하지만 GIL은 CPU의 연산 과정에서 공유 자원에 대해 발생할 수 있는 Race Condition 문제 때문에 필요했다는 걸 상기할 필요가 있다. 따라서 Python에서는 외부 연산(I/O, Sleep 등)을 하느라 CPU가 아무것도 하지 않고 기다리기만 할 때는 다른 쓰레드로의 문맥 전환을 시도하게 되어 있다. 이때는 다른 쓰레드가 실행되어도 공유 자원의 Race Condition 문제가 발생하지 않기 때문이다.
이러한 이유로, CPU 연산의 비중이 적은, 즉 외부 연산(I/O, Sleep 등)의 비중이 큰 작업을 할 때는 멀티 쓰레딩이 굉장히 좋은 성능을 보인다. 따라서 Python에서 멀티 쓰레딩이 무조건 안 좋다는 말은 사실이 아니다. 실제로, I/O 혹은 Sleep 등의 외부 연산이 대부분이라면 멀티 쓰레딩을 통해 큰 성능 향상을 기대할 수 있다. 다음 예시 코드를 보자. 멀티 쓰레딩을 통해 더 빨라진 걸 볼 수 있다.
import time
import threading
def sleep_for_2s():
time.sleep(2)
# Single Thread
start = time.time()
sleep_for_2s()
sleep_for_2s()
end = time.time()
print('[Single Thread] total time : {}'.format(end - start))
# Multi Thread
start = time.time()
thread1 = threading.Thread(target=sleep_for_2s)
thread2 = threading.Thread(target=sleep_for_2s)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
print('[Multi Thread] total time : {}'.format(end - start))
# [Single Thread] total time : 4.017191171646118
# [Multi Thread] total time : 2.002999782562256참고로,asyncio라이브러리를 이용하여 비동기 프로그래밍을 할 때 사용하는 이벤트 루프 객체의run_in_executor()메소드도 이러한 원리를 이용한 것으로 추측된다(혹시 아니라면 댓글로 지적 바람). 별도의 쓰레드에서 I/O 혹은 Sleep 등의 연산을 담당하게 하고, 이로 인해 해당 쓰레드가 블록되면 다시 다른 쓰레드로 문맥 전환을 하여 시간을 아끼는 것이다. asyncio 라이브러리를 이용한 비동기 프로그래밍과 관련해서는 여기를 참고하자.
5. CPU 연산을 병렬 처리 하는 법 (feat. GIL 우회 방법)
일반적인 CPU 연산에 대하여, 병렬 처리를 하려면 크게 두 가지 방법을 생각해볼 수 있다.
먼저, 멀티 프로세싱을 이용하는 것이다. 한 프로세스의 여러 쓰레드들은 서로 자원을 공유하지만, 여러 프로세스들은 각자 독자적인 메모리 공간을 가져서 서로 자원을 공유하지 않기 때문이다. 물론 자원을 공유하려면 할 수는 있지만, 별도의 처리가 필요하다. 다만, 멀티 프로세싱은 메모리를 더 필요로 하고 문맥 전환의 비용이 꽤 된다는 단점이 있다.
다음으로, CPython이 아닌 다른 Python 인터프리터 구현체를 사용하는 것이다. 예를 들면 Jython 등이 있다. 그러나 흔히 사용하는 방법은 아니므로 권장하지 않는다.
'파이썬 (Python)' 카테고리의 다른 글
| [Python] 비동기 프로그래밍 동작 원리 (asyncio) (52) | 2021.07.02 |
|---|---|
| [Python] 정규 표현식(정규식) 사용하기 (2) | 2021.03.04 |
| [Python] bytes, bytearray, 인코딩 및 디코딩 (0) | 2020.07.09 |
| [Python] Iterator, Generator (0) | 2020.01.11 |
| [Python] 객체와 기본 자료형 (0) | 2020.01.11 |