지금까지 CPU가 명령어를 해석하고 실행하는 방식의 단순한 구현으로서 Sequential Implementation(이하 SEQ)를 알아보았다. 이번에는 SEQ보다 훨씬 복잡하지만 성능은 월등히 좋은 Pipelined Implementation(이하 파이프라인) 방식을 살펴보자. 이것 역시 x86-64의 단순한 버전인 Y86-64를 기준으로 한다는 것을 기억하도록 하자.
1. SEQ vs 파이프라인
한 뭉텅이의 옷감을 빨래하는 과정을 상상해 보자. 그 과정이 네 단계로 이뤄져 있다고 가정하면, SEQ 방식과 파이프라인 방식은 다음 그림과 같이 비교해볼 수 있다. 왼쪽이 SEQ 방식, 오른쪽이 파이프라인 방식이다. 한 뭉텅이의 옷감은 CPU가 실행하고자 하는 하나의 명령어에 대응되며, 빨래를 위한 네 단계는 앞서 살펴보았던 Fetch, Decode 등의 명령어 실행 단계에 대응된다. 그림을 통해 파이프라인 방식이 SEQ 방식보다 훨씬 더 효율적이고 빠르다는 것을 쉽게 파악할 수 있을 것이다.

우리가 다룰 파이프라인 방식은 기본적인 명령어의 실행 단계가 Fetch → Decode → Execute → Memory → Write back이다. 이를 바탕으로 파이프라인의 명령어 실행 방식을 그림으로 나타내면 다음과 같다. SEQ와 달리, 파이프라인은 한 사이클이 한 단계만 처리하므로 클락의 주기를 훨씬 더 짧게 설계할 수 있다. 그리고 한 명령어가 다섯 단계를 모두 거쳐서 실행이 완료되어야 다음 명령어를 실행하는 구조가 아니라, 앞선 명령어가 Fetch 단계를 마무리하면 바로 다음 사이클부터 다음 명령어의 실행이 시작되는 구조이다. 따라서 이론적으로는 한 사이클 당 한 명령어의 실행이 완료되며(CPI = 1), SEQ보다 클락의 주기가 훨씬 짧기 때문에 처리 속도가 비교할 수 없을 만큼 향상된다.

2. 파이프라인 주요 이슈
2-1. Structural Hazard
한 사이클 내에 여러 명령어가 동시에 메모리 또는 레지스터에 접근할 수 있기 때문에 생기는 구조적인 문제를 의미한다. 예를 들어, 다음 그림에서 빨간색으로 표시된 부분에 주목해 보자. 네 번째 명령어가 Fetch 단계에서 메모리에 접근할 때, 첫 번째 명령어도 Memory 단계에서 메모리에 접근한다. 또한, 네 번째 명령어가 Decode 단계에서 레지스터에 접근할 때, 첫 번째 명령어도 Write back 단계에서 레지스터에 접근한다. 이러한 경우, 접근하려는 장치가 1개만 존재한다면 반드시 충돌이 발생하므로 문제가 된다.

이 문제를 해결하는 방법은 간단하다. 돈을 더 들여서 메모리 또는 레지스터를 추가적으로 갖추면 된다(Resource Duplication). 예를 들어, Fetch와 Memory 단계에서 메모리에 동시 접근하는 문제는 명령어 메모리와 데이터 메모리를 따로 갖춤으로써 해결이 가능하다. 또한, Decode와 Write back 단계에서 레지스터에 동시 접근하는 문제는 레지스터 파일을 다중 포트로 구현함으로써 해결이 가능하다. 참고로 명령어 메모리와 데이터 메모리는 그 자체로 한 번에 하나의 값만 읽을 수 있는 하나의 장치이므로, 다중 포트로 구현하는 것이 불가능하다. 반면, 레지스터 파일은 여러 개의 독립적인 레지스터로 이뤄져 있기 때문에 다중 포트로 구현하는 것이 가능하다. 이것이 레지스터가 메모리보다 1비트 당 가격이 비싼 이유이다(다중 포트를 구현해야 하기 때문).
2-2. Data Hazard (RAW Hazard)
한 명령어의 실행이 완전히 끝나기 전에 다음 명령어가 실행되기 때문에 생기는 문제로, 앞선 명령어의 실행 결과가 다음 명령어의 실행을 처리하는 데 있어서 필요한 경우에 발생한다. 예를 들어, 다음 그림에서 addq 명령어의 실행 결과인 %rax의 값은 바로 다음 명령어인 subq에서 필요로 하는 값이다. 그러나 파이프라인의 특성상, addq 명령어가 Write back 단계에 돌입하여 %rax의 값을 바꾸기 전에 subq 명령어가 Decode 단계에 돌입하게 된다. 따라서 subq는 피연산자로서 %rax의 값을 제대로 읽어오지 못하게 된다.
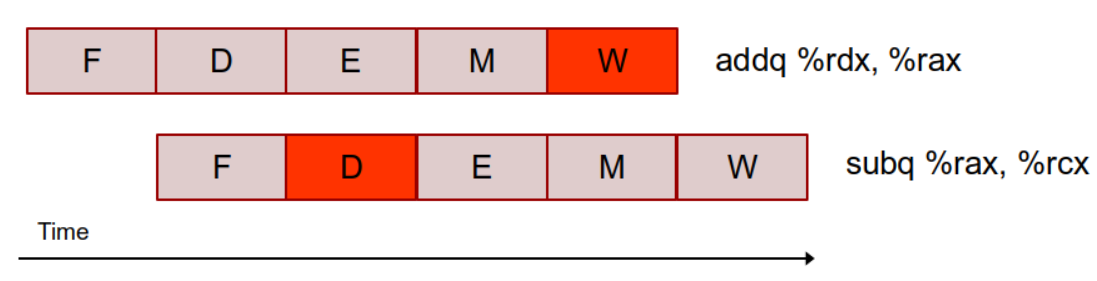
이 문제에 대한 해결 방법으로는 Stalling과 Internal Forwarding이 있다. 각각의 예시를 한 번 살펴보자.
① Stalling : 이후 명령어가 필요로 하는 값이 잘 저장이 될 때까지 버블(EX. nop 명령어)을 삽입하며 기다린다.

② Forwarding : addq의 결괏값은 Execute 단계에서, mrmovq의 결괏값은 Memory 단계에서 계산이 된다는 점을 이용하여 계산되는 값을 미리 다음 명령어에게 전달해준다. 참고로 mrmovq의 경우에는 어쩔 수 없이 한 번은 버블을 삽입해야 한다.

2-3. Control Hazard
PC의 값을 바꾸는 명령어(EX. Jump, Call, Return)를 실행할 때 발생하는 문제로, 점프할 주소를 예측할 수 없는 경우에 생기는 성능 저하 문제를 의미한다. 다음 그림의 예를 살펴보자. 점프할 주소를 알아낸 후에야 다음 명령어의 실행을 시작할 수 있기 때문에 대략 2~3 사이클은 기다리기만 하면서 낭비해야 한다.

이 문제를 해결하는 대표적인 방법 중 하나는 바로 Branch Prediction이다. 이는 조건 분기가 이뤄질 것이라고 예측하는 방법(Predict-taken)과 조건 분기가 이뤄지지 않을 것이라고 예측하는 방법(Predict-not-taken)으로 나눌 수 있다. Predict-taken의 예시는 다음과 같다. 예측대로 조건 분기가 이뤄진 경우에는 사이클이 전혀 낭비되지 않게 된다. 반대로 예측과 달리 조건 분기가 이뤄지지 않은 경우에는 실행하면 안 되는 명령어를 세 개 실행했으므로 세 사이클을 낭비한 셈이 된다. (참고로 이러한 경우에는 앞서 잘못 실행된 세 명령어가 아무 Side Effect도 발생시키지 않도록 즉시 취소되어야 한다. 이와 관련된 내용은 추후 다룰 예정이다.)

※ 참고 (CPI = Cycles per Instruction)
다섯 단계로 이뤄진 파이프라인에서 조건 분기 명령어가 전체 명령어의 대략 15퍼센트를 차지하고, 한 번의 브랜치는 세 사이클을 낭비한다고 가정해 보자. 그러면 한 명령어 당 필요로 하는 사이클의 개수, 즉 CPI는 다음과 같은 계산에 의해 1.45가 된다.
① 이상적인 경우 : CPI = 1
② 0.15 * N 개의 조건 분기 명령어 존재
③ 3 * 0.15 * N 개의 사이클이 추가로 필요
④ 따라서 CPI = 1 + (3 * 0.15 * N) / N = 1.45
'컴퓨터 구조 (Architecture) > CSAPP' 카테고리의 다른 글
| [CSAPP] Pipelining - Part 2 (0) | 2020.03.14 |
|---|---|
| [CSAPP] Pipelining - Part 1 (0) | 2020.03.11 |
| [CSAPP] Sequential Implementation (0) | 2020.03.09 |
| [CSAPP] Y86-64 - Logic Design (0) | 2020.03.07 |
| [CSAPP] Y86-64 - Basics (2) | 2020.03.05 |