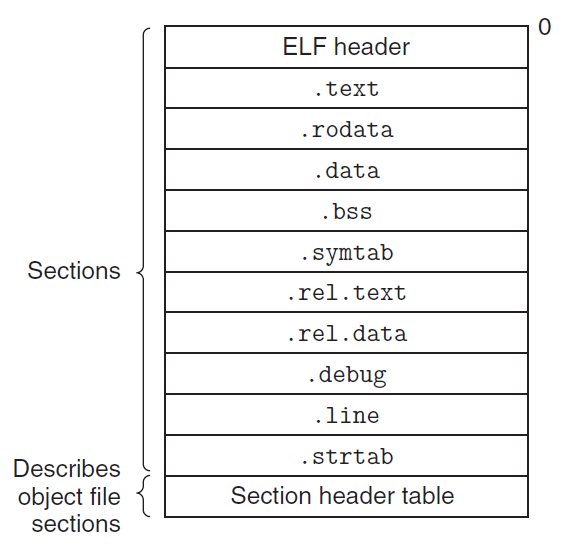
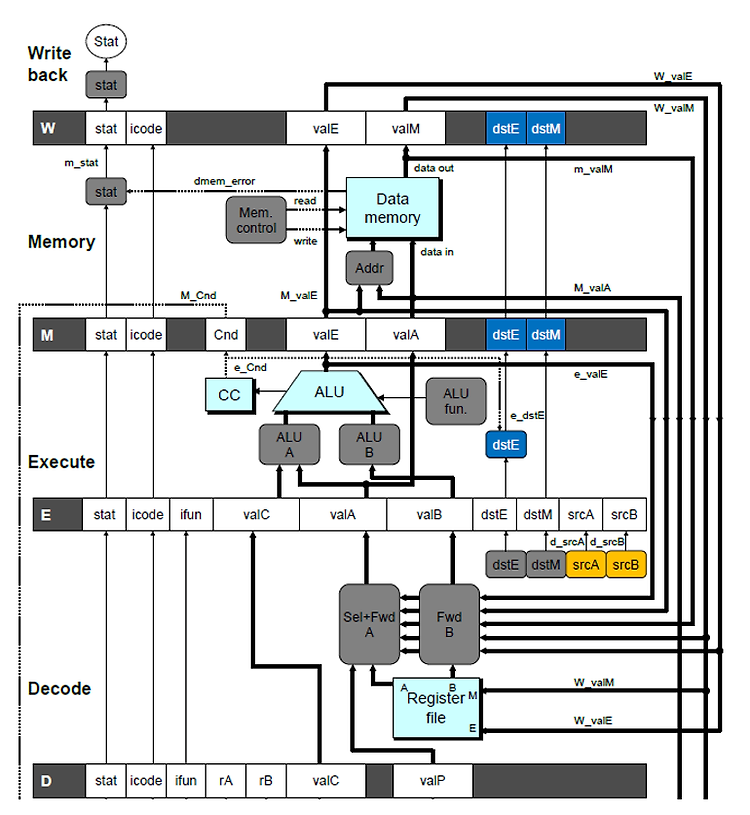
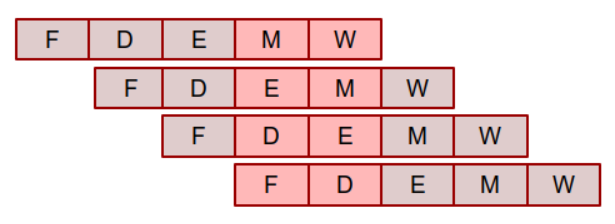
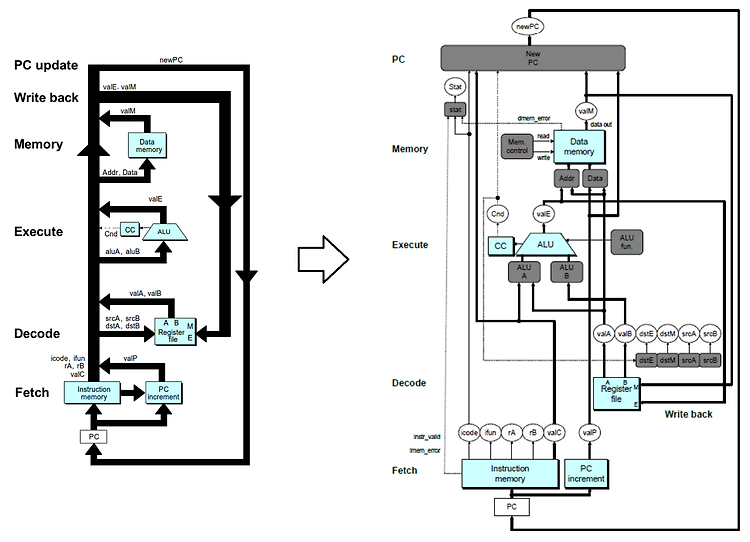
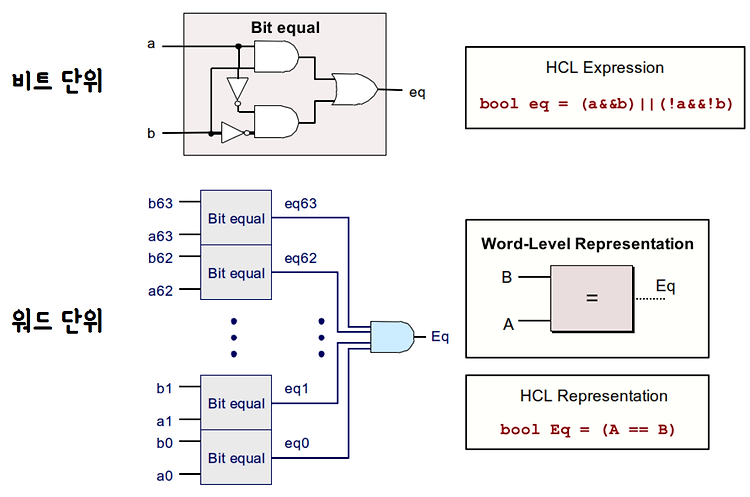
※ 링킹은 워낙 복잡한 과정이어서 CSAPP 서적에서도 아주 세부적인 내용까지는 설명하지 않고 있다. 그래서 분명 필자처럼 책을 다 읽고도 찝찝한 감정이 사라지지 않는 사람들이 있을 것이다. 그러한 사람들을 위해 링킹의 전 과정을 최대한 자세히 설명해보고자 한다(그래서 이번 포스팅은 조금 길다). 다만 책에 등장하지 않는 세부적인 내용은 필자 나름대로 이해한 것을 기준으로 설명하기 때문에 다소 부정확할 수도 있다는 점 감안해주기 바란다. (잘못된 내용 발견 시 댓글로 정정 부탁드립니다!) 1. Introduction 1-1. 링킹 (Linking) 링킹(Linking)이란 프로그램 코드 및 데이터의 조각들을 결합하여 메모리에 로드되어 실행될 수 있는 하나의 실행 파일을 만드는 과정을 의미한다. 이는 컴파..